Prolific in 2025: More precision, larger scale, and stronger safeguards for quality human data


While everyone's talking about AI replacing humans, we're seeing a different perspective: demand for high-quality, authentic human data has only been increasing.
In 2025, Prolific participants completed over 380,000 studies and tasks, ranging from 5-minute surveys on breakfast habits to complex AI model evaluations. They spent over 8 million hours contributing human judgment and insights to some of the hardest problems in AI and research.
Frontier AI labs needed our verified experts to evaluate their models. Research teams needed precisely targeted samples for credible insights. Both needed it fast.
Here's what we built to make the human intelligence layer work at the speed they need.
HUMAINE: Human-centered AI evaluation at scale
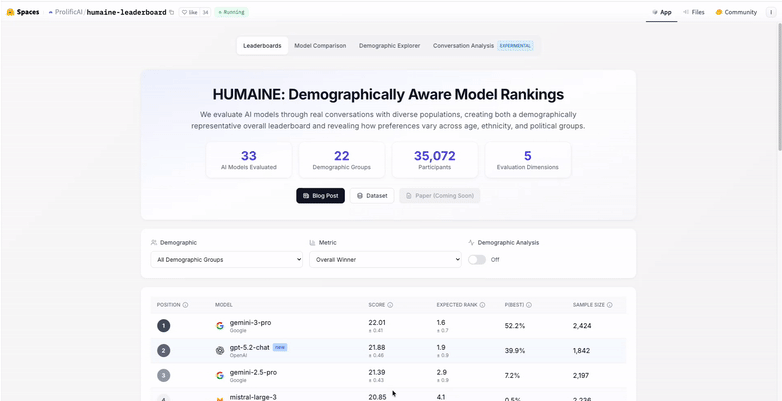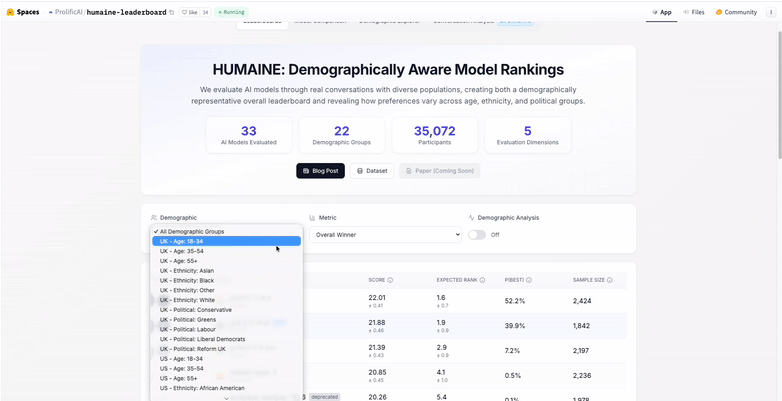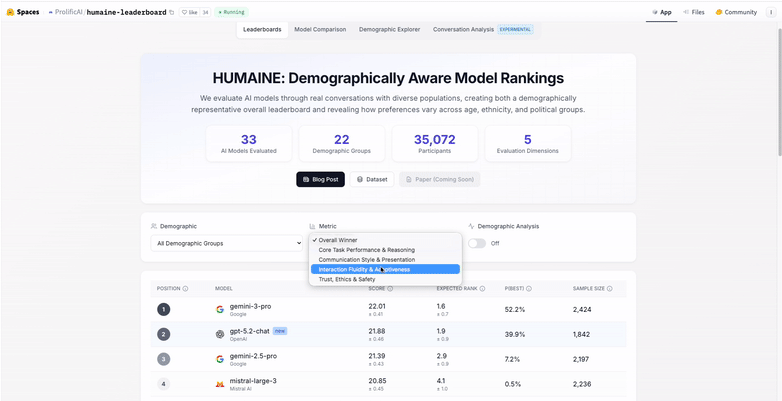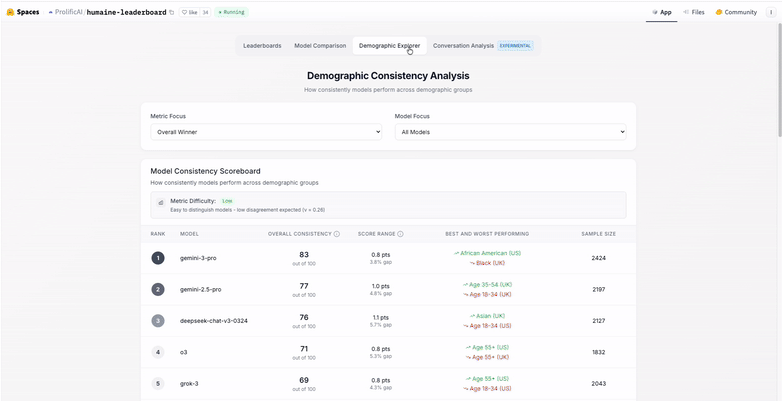
This year, we created HUMAINE, our first leaderboard that shows how real people experience AI models.
Most benchmarks ask which model is the best. We asked, "Best for whom, and why?”
Nearly 27,000 evaluators across 22 demographic groups chatted with 29 frontier models in multi-turn conversations, and delivered over 100,000 comparisons on metrics like helpfulness, accuracy, tone, safety, and ease of use.
The findings revealed what simple preference ranking misses. While Google’s Gemini 3 Pro currently leads the rankings, model preferences vary significantly by age (the largest source of disagreement) and demographics. Top models show high consistency across different demographic groups; others vary considerably.
HUMAINE proves that the evaluation methodology matters as much as the results. Evaluation design choices determine whether evals capture what people actually value or just what's easy to measure. We're now applying this expertise to help customers with complex AI training and evaluation work: methodology design, QA frameworks, and full project execution for improving AI models and agents.
As new models launch and user preferences evolve, we're excited to track how the landscape shifts in 2026. Explore the interactive leaderboard for yourself.
Stronger quality checks, more automated safeguards
Managing quality at scale is one of the hardest problems in human data collection. This year, we’ve brought in a wide range of additional checks behind the scenes to ensure each participant is human and producing high-quality responses.
- Each participant now completes over 50 identity and behavioral checks to join the pool (55% pass rate)
- Stronger ongoing verification that now includes periodic video selfie checks to confirm identity
- Real-time behavioral monitoring flags suspicious patterns
On top of this, we’ve made it easier for customers to identify low-quality submissions automatically, protecting data integrity without slowing you down.
- Auto-reject exceptionally fast submissions: Enable automatic rejection during study setup so rushed submissions are instantly replaced with new participants, or review first and bulk reject. Learn more →
- Simpler authenticity checks: Our free tool detects AI-generated content with 98.7% precision. Now with clearer setup instructions and visibility into exactly which questions were flagged. Works with Qualtrics, AI Task Builder, and Gorilla. Learn more →
From verification at the time of onboarding to in-study monitoring, these protections are part of Protocol, our five-layer defense system that combines identity verification, behavioral analysis, and real-time monitoring to ensure authentic human data. Watch our 90-second video to see how it works, or read our article to learn more about each layer.
Broader specialist pools with stronger credentials
High-quality, relevant data starts with having the right people. This year, we expanded our participant pool and strengthened how we verify their expertise. New verification methods combine skill assessments, credential checks, and task performance history to help you access deep and diverse human intelligence at the speed your work demands.
- Verified domain experts: Healthcare professionals, programmers, STEM specialists, accountants, and language experts verified using a combination of skill assessments and relevant credentials. Learn more →
- AI annotation specialists: More than 11,000 participants with proven skills in fact-checking, comparative reasoning, and structured writing, image annotation, video annotation, and audio annotation and generation. Learn more about them here.
- Global representation: Expanding to new participants from Asia-Pacific, Middle East, North Africa, and China expat communities for culturally and linguistically diverse perspectives.
More precise targeting for niche audiences
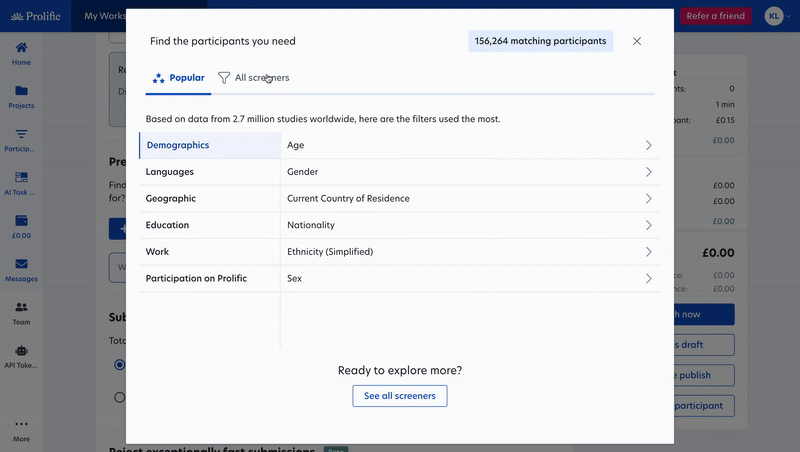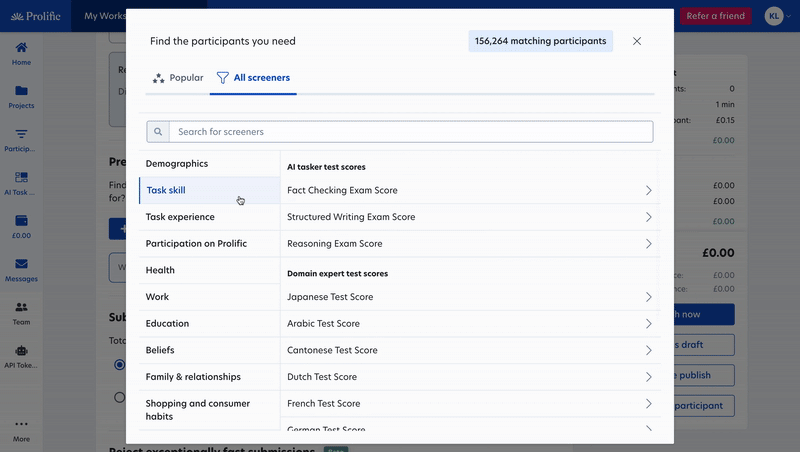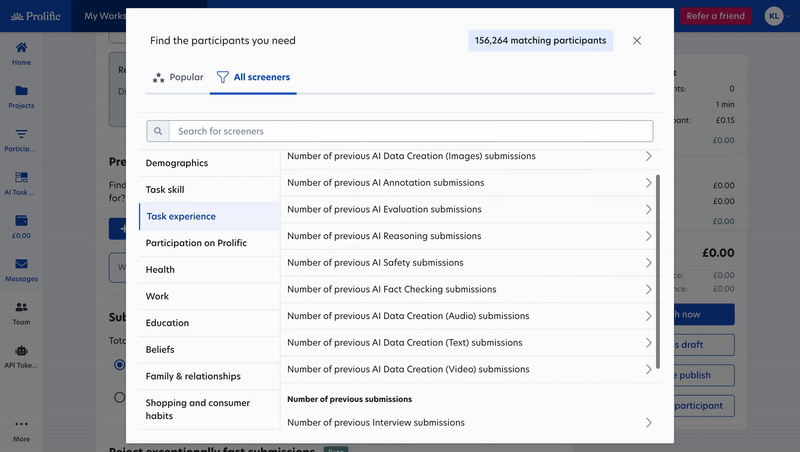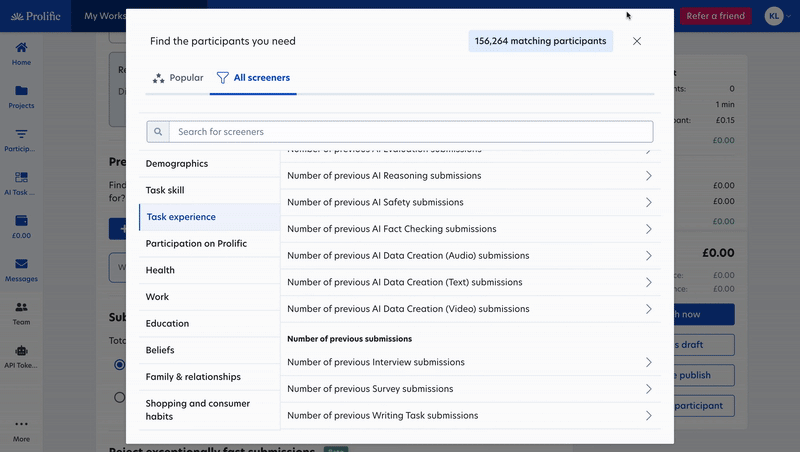
Finding the right 100 participants is more valuable than recruiting 1,000 who aren't a good match for your goals. We added new features and screeners to give you more precision in who sees your studies, so you only collect data from the right people.
- Filter by expertise and performance: Now you can also use screeners to target participants based on test assessment scores or task experience when you need more granular criteria for domain experts or AI annotation specialists.
- Natural language search: Don’t know which filters or screeners to use? Describe your target participants in plain language (demographics, skills, behaviors, etc.), and we'll automatically find and apply the right screeners.
- In-study screening with budget control: Ask participants extra screening questions to find your niche audience, pay a fixed amount per screen-out, and set screen-out limits to control costs. Learn more →
- Regional stratification (US/UK): Census-matched distribution that mirrors regional population density in one click, revealing how opinions and behaviors vary by location. Learn more →
- Expanded quota controls: Set quotas for age ranges and country of residence (both in-app and via API), with maximum strata increased from 75 to 120 for more sophisticated demographic targeting. Learn more →
Faster API integration and development
Our API lets AI teams and research platforms integrate human intelligence into their own tools and workflows: automating participant targeting, study distribution, task orchestration, and the logistics of data collection at scale.
This year, we rebuilt our API documentation to make getting started faster and staying current easier as you build and scale.
- In-browser API testing: Test calls directly in the docs without leaving the page
- Step-by-step workflow guides: Complete implementation paths for common use cases
- AI-assisted documentation: Query our docs from Claude, ChatGPT, or Cursor for instant answers while you code
Check out developer-friendly use case guides like this one on multi-part studies to automate more complex data collection projects. Explore the API docs →
Scale larger, more complex projects
Whether you're annotating thousands of data points or running multi-part studies, your data collection infrastructure needs to scale so you can handle larger or more complex datasets, iterate faster, and maintain ongoing relationships with your best participants.
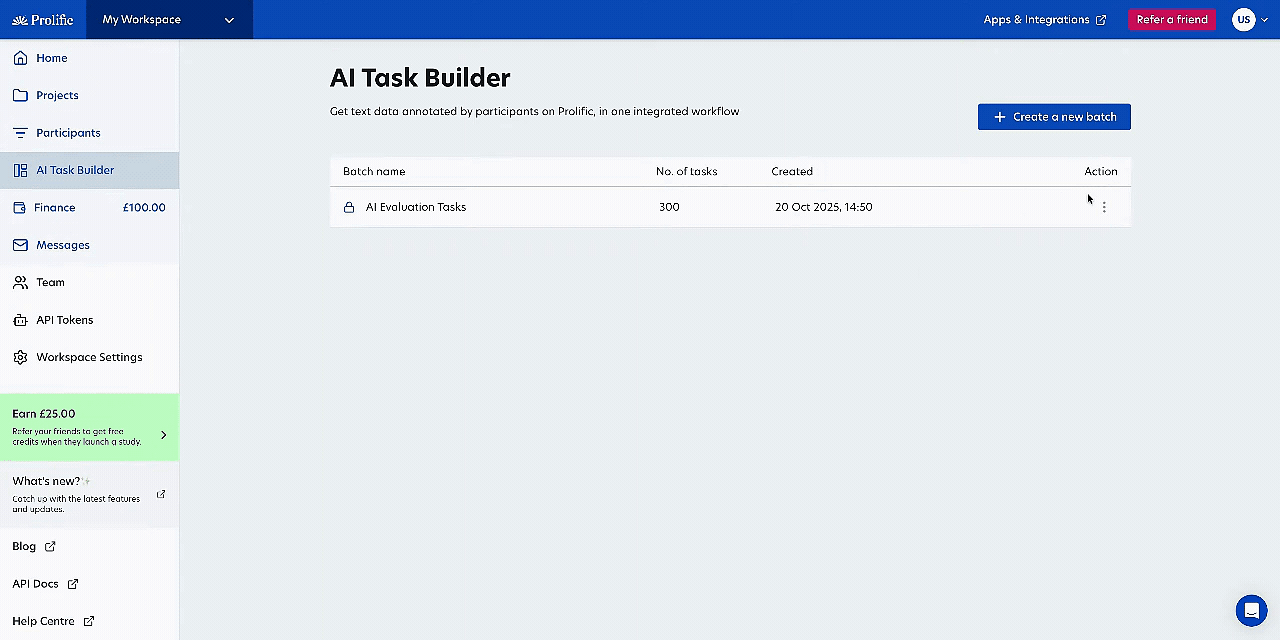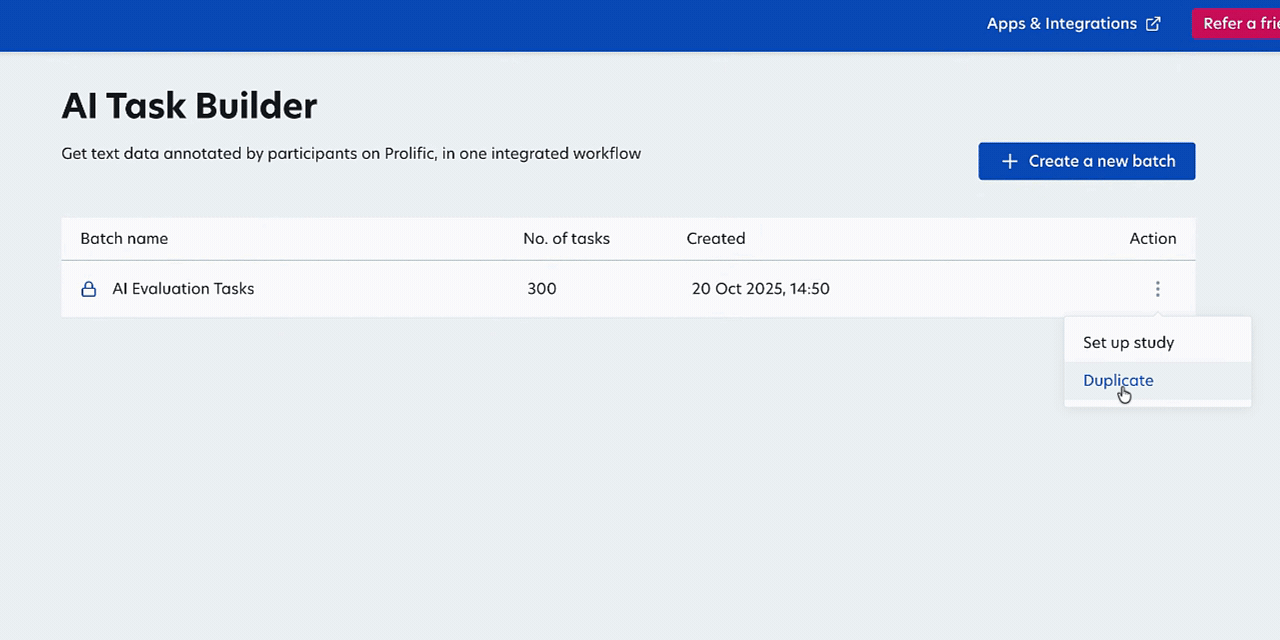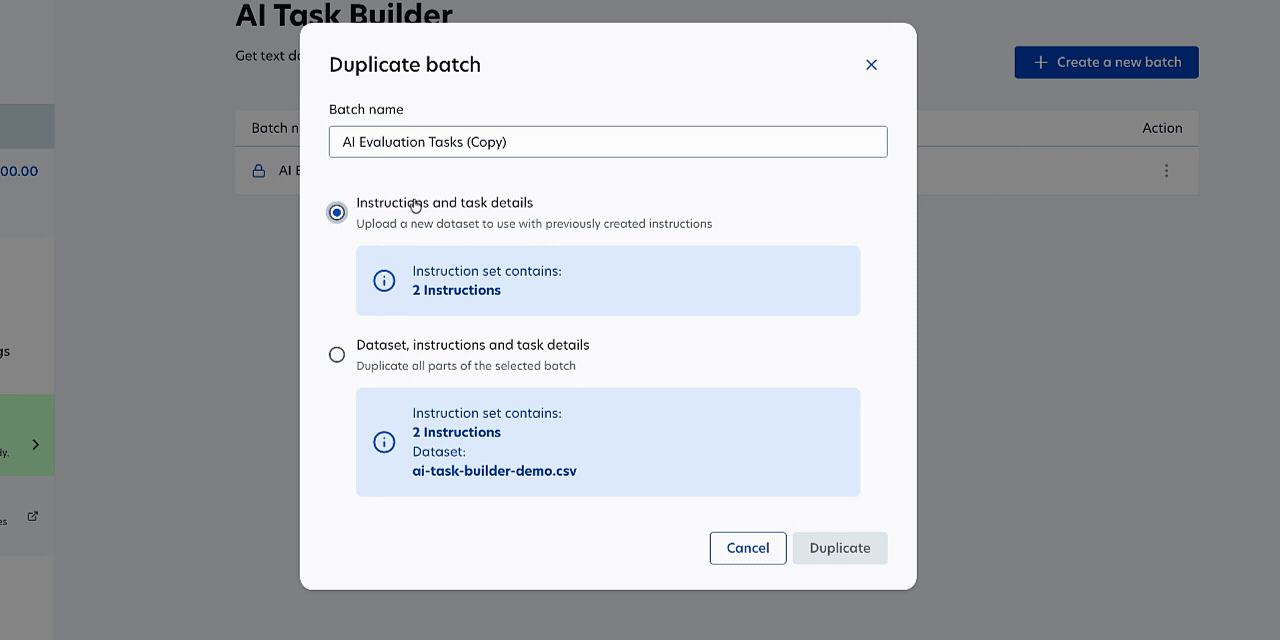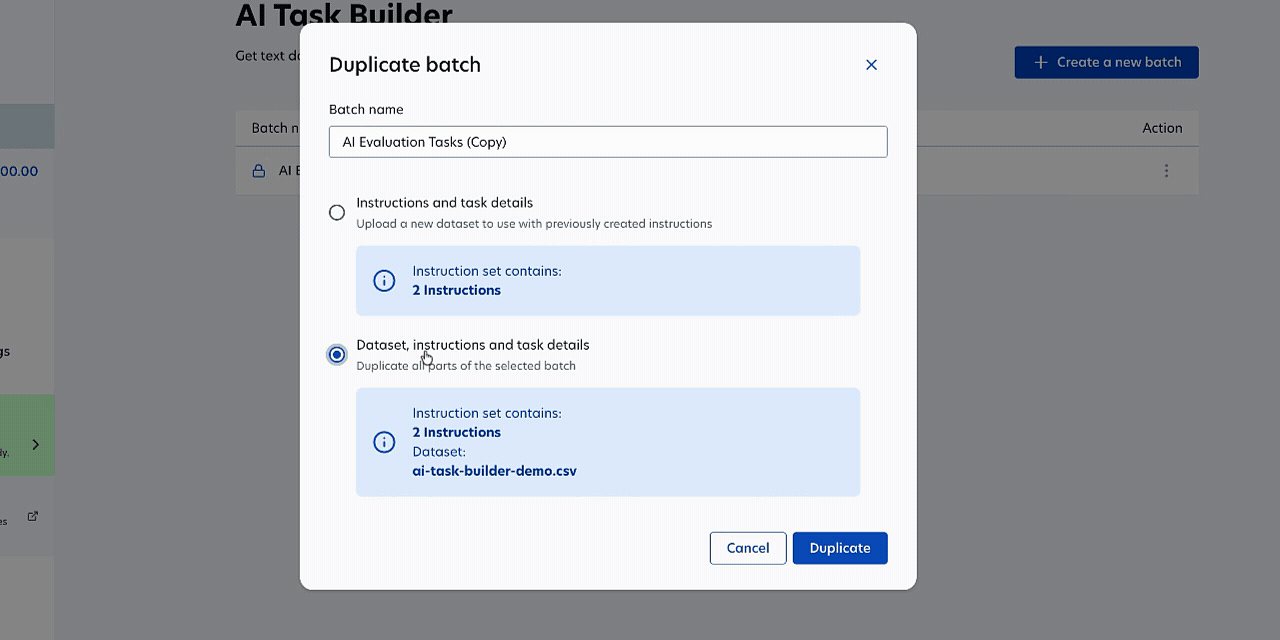
- AI Task Builder enhancements: You can now use AI Task Builder to create more complex annotation and evaluation tasks directly in Prolific. Duplicate batches to iterate faster, collect multiple annotations per task for consensus, and use quota/representative samples for demographically controlled evaluation. We’ve also improved the interface for complex text with full-screen expansion and Markdown formatting. Learn more →
- Taskflow for higher workloads: Taskflow is our intelligent task distribution system that breaks down large datasets into unique tasks for parallel completion. You can now launch up to 30,000 tasks in a single study with automatic task reallocation and performance improvements for faster data collection. Learn more →
- Create public projects: Help participants see and follow your project as you publish related studies. When participants understand how individual studies connect to broader project goals, they're more engaged. When they return for related work, they bring context from previous studies, which reduces ramp-up time and improves data quality. Rolling out gradually with more features coming soon. Learn more →
What’s next
2025 showed how it’s possible to create a human intelligence layer that powers both groundbreaking research and trains and evaluates frontier AI models. In 2026, expect bigger capabilities, expanded teams, and more ways to work with expert human intelligence at scale.
Subscribe to product updates in your marketing email preferences to stay in the loop.