What's New: Expanded quotas, in-study screening, and smarter quality controls

Welcome to our August 2025 product updates!
This past month, we've focused on giving you more precision and control over every aspect of your research, from participant targeting to quality assurance. Whether you're collecting data for AI evaluations or running studies with complex screening criteria, these new features will help you collect better data with less manual oversight.
Read on to see what's new with Prolific this month.
Introducing in-study screening that sticks to your budget
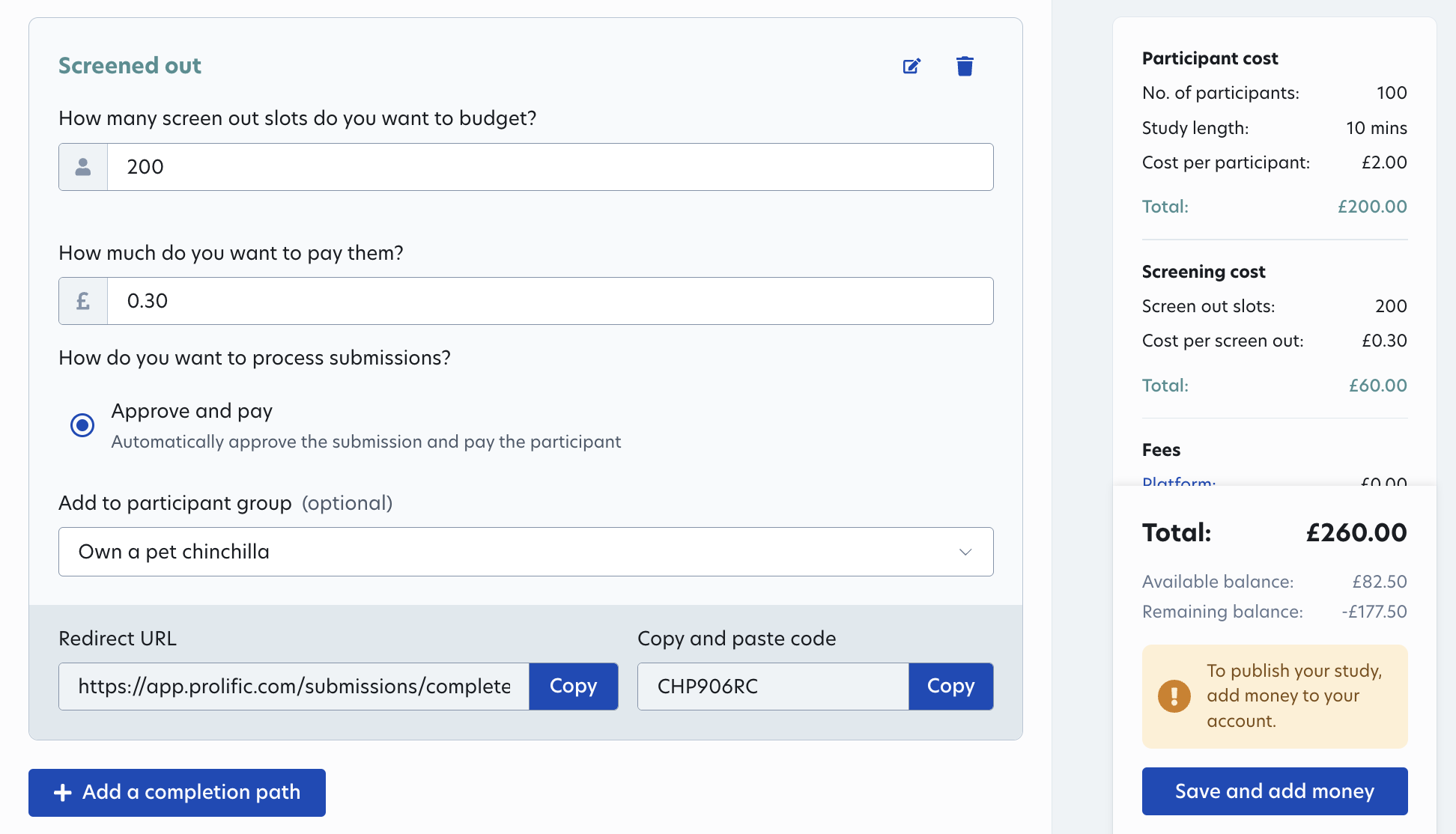
We’ve now released a new version of in-study custom screening that lets you have complete control over how much you pay for screen-outs. This feature is now available to all Prolific users and workspaces, both in-app and via the API.
- Frictionless yet fair. Automatically screen out and pay a fixed amount to participants who don’t fit your custom screening requirements.
- Set your budget for screening. Pay a fixed amount per screen-out (e.g. $0.20), and add a screen-out slot limit. If the limit is reached before your study is full, it’ll pause for you to decide next steps.
- See total costs upfront. Screened-out participants are paid automatically, and unused slots are reimbursed.
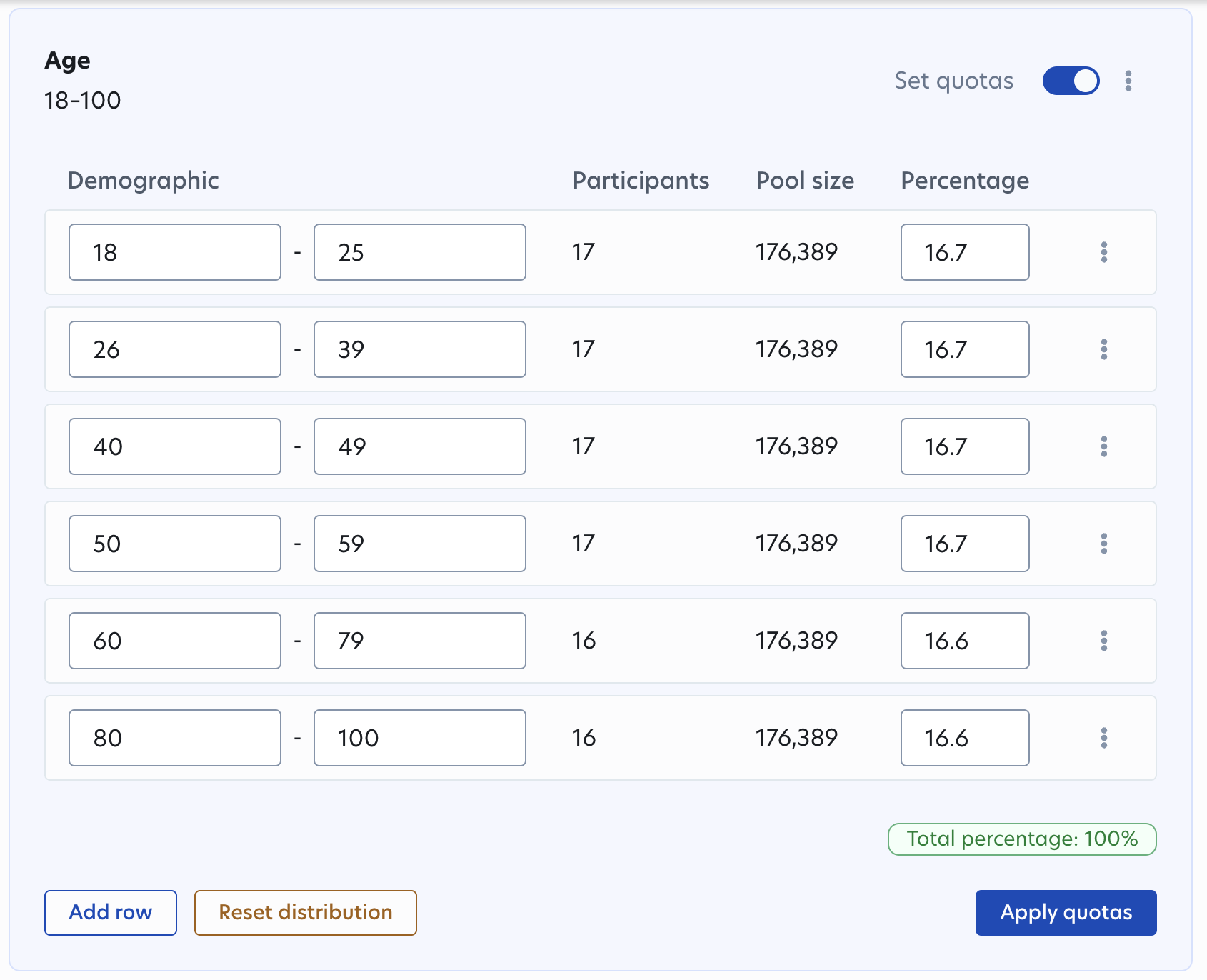
More precise targeting with expanded quotas
Getting the right participant mix just got easier. We've launched many improvements to quota studies that give you more control over your sample composition:
- Set quotas for age ranges and country of residence: Two of our most requested quota types are now available directly in-app. Previously, country of residence quotas were only accessible via API, but this is now available to all users in the UI.
- Create more complex breakdowns: We've now increased the maximum quota strata from 75 to 120, allowing for more sophisticated demographic controls.
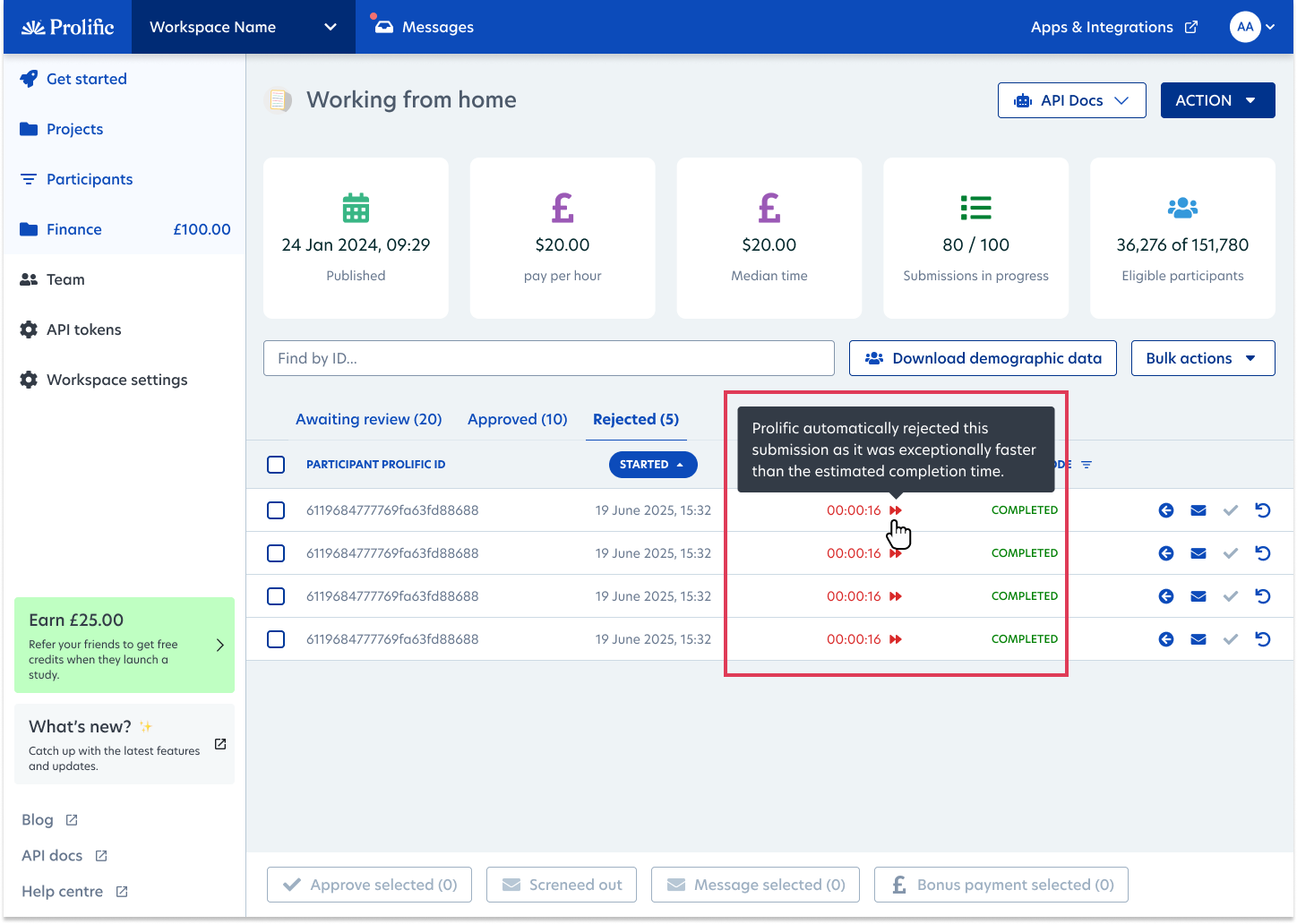
Automatically reject and replace exceptionally fast submissions
Rushed submissions often indicate low-quality data, especially for complex studies and tasks requiring thoughtful responses. Submissions completed in unrealistic timeframes are now automatically tagged as "exceptionally fast," making quality issues easy to identify and address.
- With this release, you can enable auto-rejection during study setup, so “exceptionally fast” submissions are instantly rejected as they come in and replaced by new participants.
- If you wish to review responses before rejecting, you can keep auto-rejections toggled off and still bulk reject exceptionally fast submissions.
We’re rolling this out in-app and via the API over the coming week. To use via the API, go to ‘Create a draft study’ > expand ‘submissions_config’ > see ‘auto_rejection_categories’. Learn more.
Accelerate data throughput by increasing maximum submissions
When submissions are slower than expected, or when you have a pool of high-quality participants willing to contribute more, limits on maximum submissions can hold back your data collection.
Now you can adjust submission limits on live studies via API without interrupting data collection by adjusting the max_submissions_per_participant. Check out our API documentation here.
10X your qualitative research with Chatty Insights
Prolific is now directly built into Chatty Insights, a platform that lets you run AI-moderated interviews in text, audio, or video formats at a large scale.
With this integration, you can recruit diverse participants from across the globe to test ideas, validate marketing campaigns, and understand your audience better - all while reducing the time to insights by 90%.
More Prolific news
In the Loop: An exclusive dinner for human data experts in AI
Join Prolific and Encord on September 10, 2025, in San Francisco for an exclusive dinner for human data experts in AI. Connect with fellow experts, share best practices, and explore emerging opportunities in AI evaluation. Reserve your spot - places are limited.
Webinar recording: Why AI leaderboards miss the mark
AI leaderboards face criticism for gaming, under-representation of open-source models, and misalignment with real-world utility. We hosted a discussion with Cohere's Oliver Nan (first author of "The Leaderboard Illusion" paper) and Dr. Hua Shen from the University of Washington on where leaderboards fall short and how to use them more effectively. Watch the full discussion.
Case study: Benchmarking LLM emotional intelligence
Evaluating AI requires rich human data as a baseline. See how University of Bristol researchers used Prolific to gather authentic emotional judgments from 1,000+ participants and create a human benchmark to assess LLM models’ emotional intelligence. Read the full case study.