Authenticity checks: How we tested the most accurate method for identifying agentic AI


This article summarises how Prolific ran internal testing of new bot authenticity checks, which detect AI agents in online surveys. The internal testing found that authenticity checks outperformed all other tested methods for identifying AI agents, achieving 100% accuracy.
The biggest AI threats to online research
Artificial intelligence is changing the online research landscape. For years, researchers have dealt with inattentive participants and low-quality responses, and data quality has always been a top concern. But recent advancements in AI have raised concerns about data quality: how can we be sure that survey responses are from humans rather than AI?
There are really two separate threats when it comes to AI. And one is much more common than the other right now.
The more common threat seen today is human participants using LLMs (like ChatGPT) to generate responses to free-text questions. Studies have documented this behavior, and detection rates suggest it’s widespread (Veselovsky et al., 2024; Rilla et al., 2025). However, there are effective methods to detect and reduce this, such as Prolific’s initial LLM authenticity check, released in May 2025.
The currently less common threat is fully autonomous AI agents completing entire surveys, though recent work has shown it’s technically possible (Westwood, 2025).
Westwood's paper demonstrated that it is technically possible for AI agents to successfully navigate surveys and produce responses that seemed human, convincingly impersonate demographic characteristics, and pass traditional quality checks. The paper didn’t examine or prove that agents are currently flooding sample providers, but it does prove that the fundamental capability exists.
As providers of online participants, it’s of the utmost importance that our researchers can trust that the data they receive is human. That’s why we’re always working on solutions that stay ahead of these issues.
Introducing authenticity checks
In May 2025, Prolific created its first authenticity check, which showed strong detection rates for participants using AI to answer open-ended questions. We call this the “LLM authenticity check”, and it examines over 15 different behaviors, such as copy-pasting and tab-switching, to determine whether the participant is giving an authentic answer or using AI. In our testing, these checks achieved 98.7% precision and a 0.6% false-positive rate.
Since then, we’ve been working on a high-accuracy method to detect AI agents pretending to be human participants. In February 2026, we’ve launched new “Bot authenticity checks” that look for non-human or automated environments across all survey question types. In our testing outlined below, these checks successfully detected five mainstream and custom AI agents with 100% accuracy.
Both of these checks are available now for use with studies set up in Qualtrics.
How we tested bot authenticity checks versus other solutions
Our sciences team at Prolific ran a study to test whether our latest bot authenticity check can reliably distinguish humans from AI agents, and how it stacks up against other commonly used detection methods.
What we tested
We built a survey in Qualtrics that looked like a standard online research study, with questions from established psychology tasks, personality scales, and some custom items. Hidden within the study were seven different detection methods:
- Four attention check questions: The classic "please select 'strongly agree' to show you're reading this" type questions.
- Two consistency checks: Paired questions where humans should answer in predictable patterns. For example, if the answer to one question was true, the other had to be false (and vice versa) because it indicates consistency.
- Two reverse shibboleth items: Questions that your intended sample (i.e., humans) should not know the answer to, but an AI agent likely would.
- Three cognitive traps: These are visual illusions designed to exploit fundamental limitations in vision-enabled AI systems. We used a modified Müller-Lyer illusion, a modified cafe wall illusion, and a ‘moving robot task’, all of which have been shown to be highly discriminative between AI agents and human participants (Affonso, 2025).
- Comprehensive mouse tracking: Recording every cursor movement and click pattern throughout the survey.
- Qualtrics' reCAPTCHA score: The platform's built-in risk scoring system.
- Prolific’s new bot authenticity check: Our proprietary detection system that uses real-time analysis to detect non-human or automated behaviors.
The participants
We recruited 125 human participants through Prolific, filtering for those with the highest approval ratings to make sure we had genuinely human respondents. This gave us a clean baseline of verified human responses.
The AI agents
We tested five different AI agents, each completing the survey 25 times to match our human sample size:
- GPT Agent: OpenAI's GPT configured to complete surveys
- Claude: Anthropic's Claude accessed via Cursor
- Perplexity: Perplexity AI's search-enhanced agent
- Gemini: Google's Gemini via Project Mariner
- Custom Agent: Our in-house ‘white hat’ agent, designed by Prolific’s AI research engineers to take surveys and avoid detection
The custom agent was crucial to include because it’s specifically designed to take surveys undetected. It’s closer to Westwood’s bot (2025) as an adversarial, customisable agent than the more readily detectable commercial AI agents.
To take part in the survey, we provided all agents with an identical prompt that asked them to complete the survey as a human would and exhibit human-like behaviour.
How we measured success
For each detection method, we calculated classification accuracy, i.e., the percentage of respondents (both human and agent) that were correctly identified.
- ≥90% = High
- 70–89% = Moderate
- <70% = Low
We also report sensitivity (the percentage of agents caught) and specificity (the percentage of humans who correctly pass).
The results
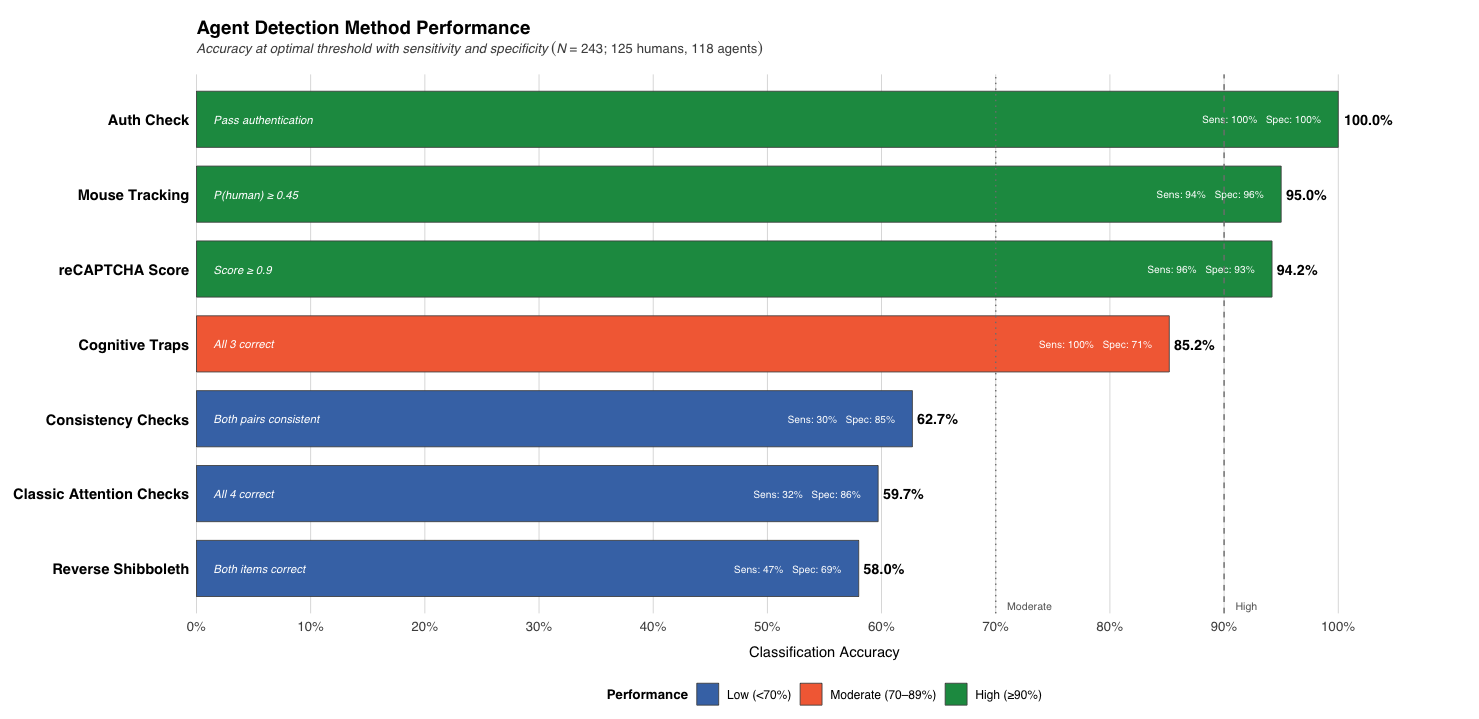
Prolific’s bot authenticity check (100% accurate)
Our authenticity check achieved perfect classification with 100% sensitivity and 100% specificity. Every single agent was caught; every single human passed through. This was the most effective method we tested.
Mouse tracking (95.0% accurate)
Tracking cursor movements proved highly effective, with 94% sensitivity (agents caught) and 96% specificity (humans correctly passed). Humans and agents showed distinctly different behavior:
- Movement: Humans averaged 85 mouse movements per page; most agents made just 6–10
- Direction changes: Human cursors were more erratic, whereas agent cursors moved directly
- Velocity: Humans showed higher peak speeds; agents were more consistent
While this is promising, the mouse metrics and thresholds likely need to be calibrated for each survey, meaning there is no ‘golden number’ of moves or clicks that would reliably indicate an agent across all surveys. Each survey has different question counts and page counts, so a shorter survey would have fewer clicks on average, but this depends on the individual survey.
Qualtrics’ reCAPTCHA score (94.2% accurate)
Qualtrics reCAPTCHA performed well, scoring humans much higher (mean average 0.98) than agents (mean average 0.69). At a threshold of 0.9, it caught 96% of agents and passed 93% of humans. That's still a strong performance, but it incorrectly flags more innocent participants than authenticity checks or mouse tracking.
Cognitive traps (85.2% accurate)
The visual illusion tasks achieved 100% sensitivity, i.e., not a single agent passed all three traps. However, specificity was only 71%, meaning nearly one in three genuine humans were incorrectly flagged. That's a significant false-positive rate that could lead to unnecessary exclusion of real participants from your research. This tradeoff between catching all agents and falsely flagging humans resulted in lower overall accuracy.
Consistency checks (62.7% accurate)
These check whether respondents give logically consistent answers to paired questions, providing moderate discrimination.
For example, we included a scale near the start of the survey that said ‘I prefer to work in teams rather than alone’ and participants had to indicate their agreement. In a separate scale, we later included the item ‘I prefer to work alone,’ and participants answered true or false. If one were true, the other would have to be false (and vice versa), because that indicates consistency.
With only 30% sensitivity but 85% specificity, this method rarely flagged humans incorrectly but missed most agents. Humans were consistent 85% of the time, while agents ranged from 27% to 91%.
Classic attention checks (59.7% accurate)
Traditional attention checks achieved just 32% sensitivity and 86% specificity, they rarely caught agents but did avoid flagging humans. A significant proportion of AI agents passed easily:
- Humans: 86%
- Agents: 68%
Attention checks were designed to catch inattentive humans and not AI agents, so it’s no surprise that these are ineffective. However, it’s still important to note that they shouldn’t be relied upon for AI agent detection.
AI systems are very good at following simple instructions, and some AI agents actually outperformed humans on these checks. Only our custom agent failed them at a significant rate.
Reverse shibboleth questions (58.0% accurate)
These questions should receive an "I don't know" answer, and showed the weakest performance. With 47% sensitivity and 69% specificity, these performed barely above chance. Several AI agents answered more correctly than humans (68.8%), including Perplexity (78.3%), Claude (73.9%), and the custom bot (87.5%). This likely reflects how AI systems are trained to express uncertainty.
This demonstrates they are not useful as a detection method, and likely reflects how AI systems are trained on fact-checking and expressing uncertainty.
Key findings
The results clearly demonstrate that not all detection methods are created equal when it comes to AI agents.
Prolific’s bot authenticity check achieved perfect separation, even against our custom adversarial agent that was specifically designed to evade detection. Cognitive traps and mouse tracking also performed excellently and offer strong alternatives where authenticity checks aren't available.
However, traditional quality measures, such as attention and consistency checks, can’t reliably distinguish humans from AI because they weren't designed for this.
What this means for your research
Based on these findings, here's what we'd recommend:
- Don’t rely solely on traditional quality checks. They're still useful for catching distracted humans, but new checks require more sophisticated methods to detect AI agents.
- Validate different detection methods. As this study shows, there's a huge performance gap between detection methods. Don't assume something works and look for empirical evidence.
- Layer multiple methods where possible. Combining authenticity checks with mouse tracking, reCAPTCHA, or cognitive traps provides stronger protection and helps you identify quality issues in your data. Relying on a single method can also unfairly flag innocent participants, unless you use a method like authenticity checks, which have an exceptionally low false-positive rate.
- Don't panic, but be proactive. Westwood (2025) was right to sound the alarm about AI agents, but our study shows that effective detection exists. Using robust methods, such as authenticity checks, can still deliver trustworthy data.
Prolific’s approach to detecting AI agents
Ensuring high-quality participants is part of Prolific’s DNA, and something we’ve prioritized since Prolific started in 2014. The AI landscape is vast and growing rapidly, and what works to detect agents today may not work in time. That’s why we have a dedicated team constantly working to stay ahead of emergent threats to data quality.
Detecting AI agents is a solvable problem, and authenticity checks prove this. We can achieve discrimination between humans and agents, and as we build more solutions to tackle this problem, our detection will improve further.
Sign up to Prolific to try authenticity checks today.
Learn how to set up Prolific’s authenticity checks.
References
Affonso, F. M. (2025). Detecting Vision-Enabled AI Respondents in Behavioral Research Through Cognitive Traps. https://doi.org/10.2139/ssrn.5766848
Rilla, R., Werner, T., Yakura, H., Rahwan, I., & Nussberger, A.-M. (2025). Recognising, Anticipating, and Mitigating LLM Pollution of Online Behavioural Research. ArXiv.org. https://arxiv.org/abs/2508.01390
Veselovsky, V., Ribeiro, M. H., Cozzolino, P., Gordon, A., Rothschild, D., & West, R. (2023). Prevalence and prevention of large language model use in crowd work. ArXiv.org. https://arxiv.org/abs/2310.15683
Westwood, S. J. (2025). The potential existential threat of large language models to online survey research. Proceedings of the National Academy of Sciences, 122(47). https://doi.org/10.1073/pnas.2518075122







