Human-centered evaluation for voice and conversational AI
Trusted by


Measuring what really matters
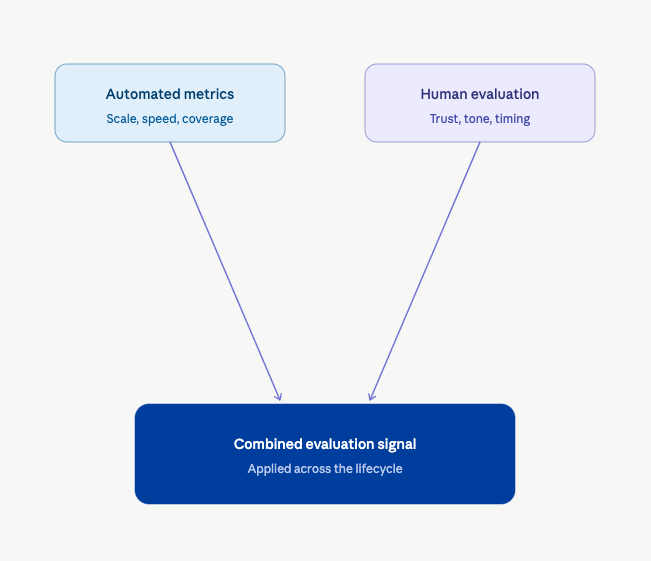
Conversational AI is advancing fast. LLM-powered chat and voice agents are more fluent and more capable than ever, and they often score well on automated metrics. But strong scores don't tell you whether a conversation felt clear, whether a refusal landed right, or whether a delay broke the flow.
The qualities that decide whether people trust a conversation are perceptual. Clarity, tone, timing, and whether someone feels understood rather than managed all depend on human judgment and context. They surface when real users interrupt, change their minds, and react to what they hear, not in scripted tests.
That's why modern evaluation combines automated metrics with structured human validation. Not as a final check, but as a signal you can apply throughout the evaluation lifecycle.
Built for modern conversational AI use cases
See Prolific in action
For teams running continuous evaluation or deploying at scale, Prolific integrates directly into existing pipelines. Use our API or partner ecosystem to bring human judgment into your workflows without slowing development.
Prolific platform overview
AI Task Builder by Prolific
Get set up, target the right participants, and launch tasks, surveys, or experiments in your tools in minutes.




