What's New: Flexible audience targeting, expanded participant pool, and more


This month, we've introduced new ways to build more precise audiences, grown our participant pool, and continued our push to protect your data from bots and AI agents.
Read on to see how March's updates benefit your research.
Target more complex audiences with flexible screener logic
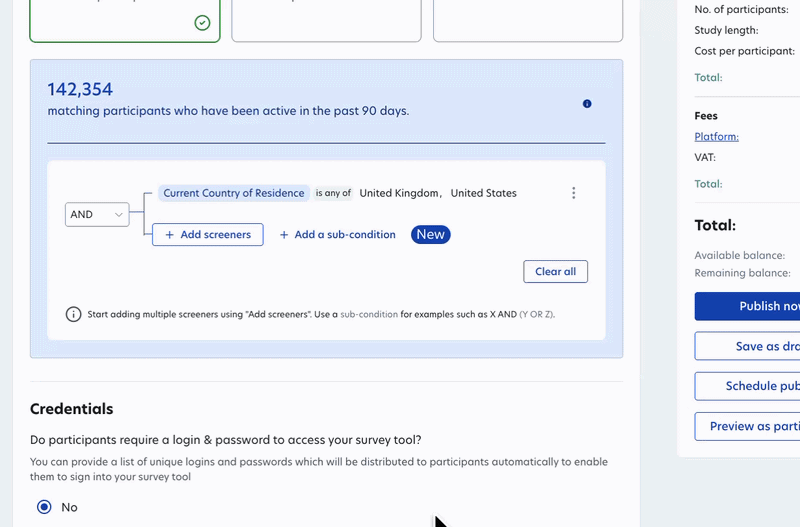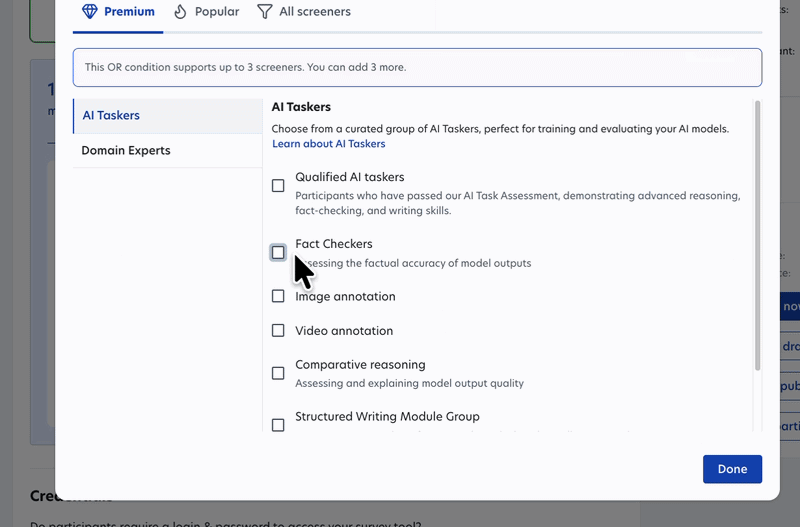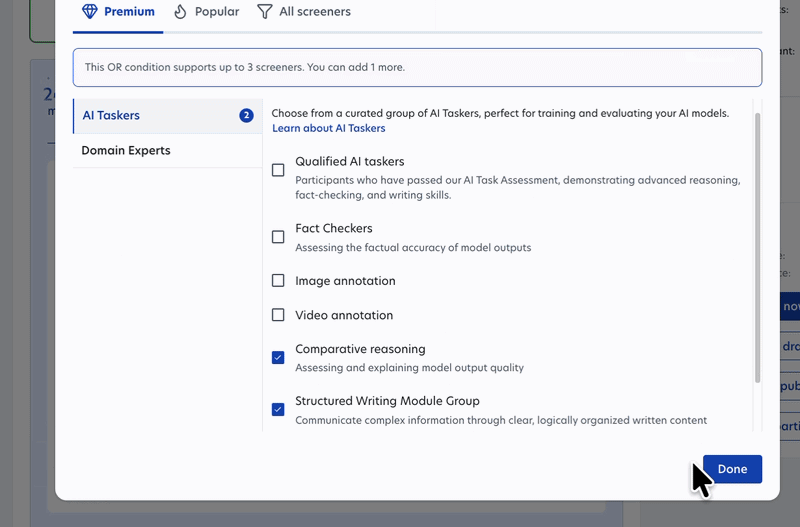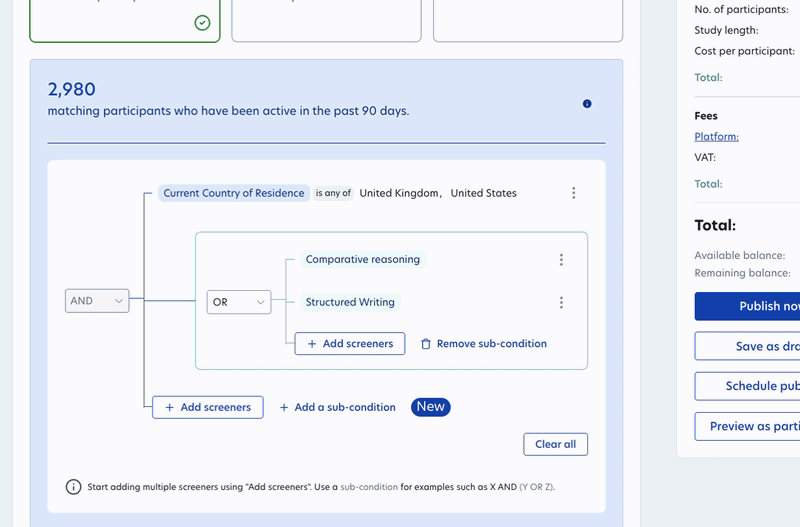
You can now combine screener attributes and participant groups using OR logic in a single study.
Previously, reaching participants that fit different profiles meant running separate studies. Now you can define those conditions together, keeping your study setup simpler and saving you time on setup and analysis. This logic works across all screeners, saved participant groups, AI Taskers, and Domain Experts.
We're gradually rolling out this feature to all users over the coming weeks, so if you don't see it in your account yet, it's on its way.
Reach more participants across more markets
Our active participant pool has grown to 220,000+ participants, with strong growth across the US, Spain, Canada, France, Sweden, Brazil, Chile, Mexico, Japan, and more.
We've also continued expanding our specialist participants:
- Language experts: 500+ speakers of Portuguese, Arabic, French, Polish, and Mandarin; 300+ in Korean, Dutch, and Japanese; and growing numbers of Cantonese, Urdu, Hindi, and Russian speakers.
- New AI Taskers and Domain Experts: 1,500+ Comparative Reasoning experts for assessing and explaining model output quality, plus 80+ finance experts, 70+ accountants, and 100+ lawyers.
You can find these specialist participants under Domain Experts in the app or via API.
Protect your data from bots and AI agents
LLM-powered bots and AI agents can now complete entire surveys autonomously, putting your data quality at risk. Our bot authenticity checks use real-time behavioral analysis to detect when automated scripts or agents are completing your study, across all question types and with 100% accuracy in our testing.
The checks run alongside our existing LLM authenticity checks, which detect when participants use AI tools to write free-text answers (98.7% precision). Together, they ensure your data reflects genuine human responses.
Want to go deeper? We're running a webinar series on how to bot-proof your research. The first episode, on the scale of LLM threat to online research in academia, is now available to watch on demand. And you can also register for our two upcoming sessions:
- 19th March | 4:30pm GMT — How to verify participants on Prolific with Dr Simon Jones
- 26th March | 5pm GMT — Live demo: See how authenticity checks detect agentic AI, and how to use them in your next study
Sign up here to save yourself a spot.
The Frontier: More from Google DeepMind on Deliberate Lab
In our latest episode, Jerome Wynne, Senior AI Research Engineer at Prolific, continues his conversation with Crystal Qian, Senior Research Scientist and PAIR team lead at Google DeepMind, on Deliberate Lab — the open-source platform for large-scale, real-time behavioral research on human and LLM group dynamics.
They cover the practicalities of running synchronous studies with live cohorts, the decision to open-source Deliberate Lab, and what's coming next for the platform. Crystal closes with a thought worth sitting with: Don't chase the AI frontier. Focus on the human part, because that's the part that changes slowly enough to study.
Save study drafts with fewer required fields
Getting started on Prolific just got a little easier. Previously, saving a draft study required filling in several fields upfront, including a study URL. Now, all you need is a study name and participant count, so you can explore the platform and come back to the details when your data collection tool is ready to go.
We'll be releasing this to all workspaces over the next few weeks, so look out for it in the Prolific app.







