What AI practitioners told us about the real bottleneck in AI development


Ask any AI team what they're building for 2026, and you'll hear the same answer. Agents.
Earlier this year, we surveyed over 320 AI practitioners working across frontier labs, Fortune 500s, and AI-native startups, then screened for direct, hands-on involvement with AI systems and ended up with 121 qualified experts. When we asked them which areas of AI they expected to see the most growth over the next 12 months, AI agents and autonomous systems ranked first in every other category. Enterprise AI scaling, multimodal capabilities, and infrastructure tooling all trailed behind. The industry has made its bet.
What that bet actually requires is less widely understood.

A chatbot that produces a confused response wastes a few seconds of someone's time. An agent that books the wrong flight or files the wrong contract creates a problem the user has to spend the rest of their day undoing. Reliability becomes the whole product. The model has to interpret intent correctly the first time, in contexts the developer never explicitly trained it on, and that depends on the quality of the human signal used to teach it what good judgment looks like.
Our research suggests the industry knows this and is failing at it anyway. Compute is no longer where teams are stuck. The bottlenecks they're reporting now are almost all human-shaped, and they add up to something we've started calling a calibration crisis.
Where AI teams are actually stuck
About half of our qualified respondents identified as AI engineers or researchers (the people writing the code and training the models), and over a fifth were running AI systems in scaled production environments. These were the people building AI systems day to day, and they were unusually consistent on what was slowing them down.
Let’s start with what isn't on the list.
Cost is not slowing them down. When we asked practitioners to name the most significant challenges they face in their area of AI, cost management came in dead last. Only around one in six respondents flagged it. As we wrote in our piece in Business Reporter earlier this week, that finding cuts against years of received wisdom about where AI budgets are most constrained.
So if cost isn't where teams are stuck, where are they?
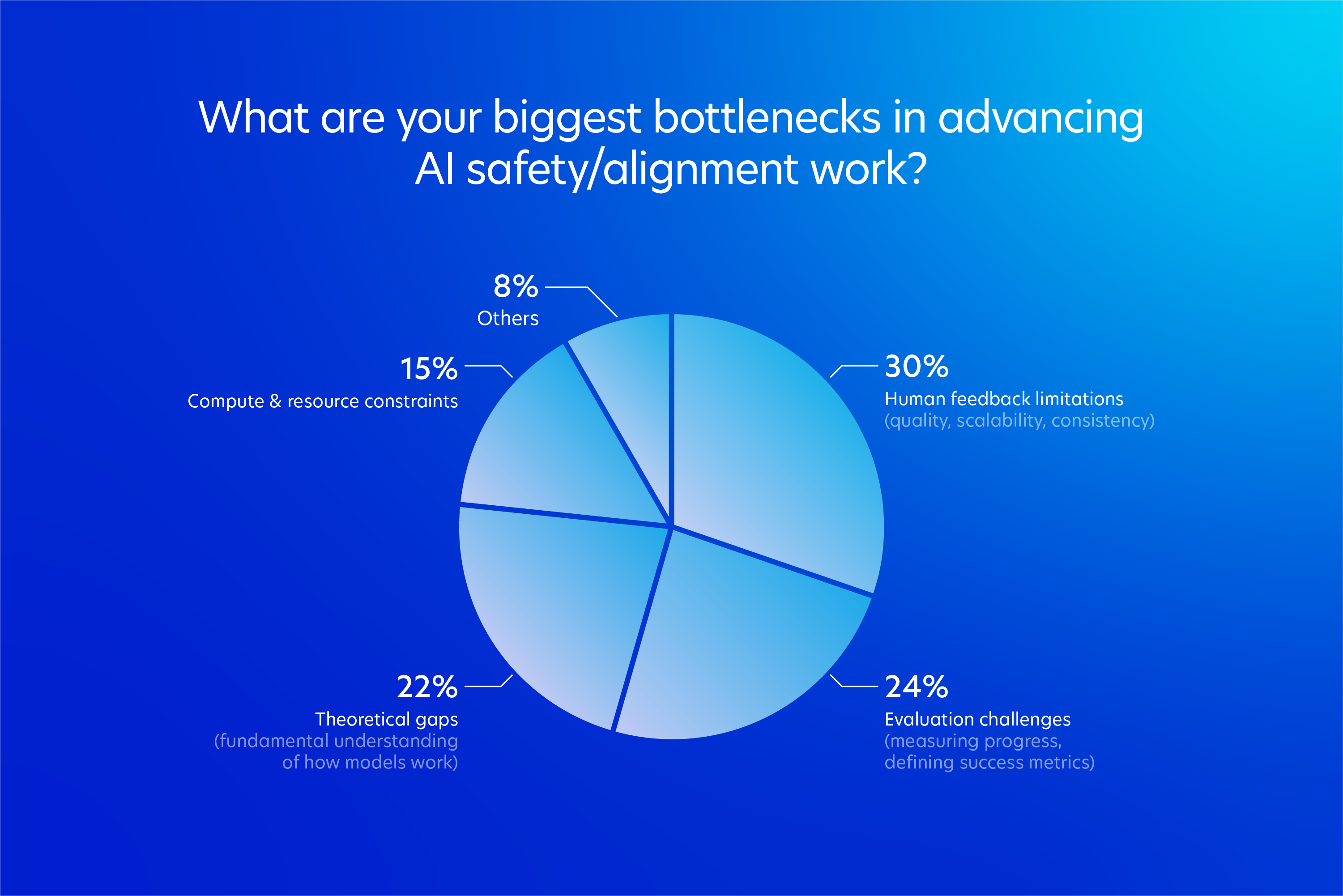
When we asked the same group about their biggest bottleneck in advancing AI safety and alignment work, the top answer was human feedback limitations at 30%, covering quality, scalability, and consistency. Evaluation challenges came next at 24%. Theoretical gaps in understanding how models work followed at 22%. Compute and resource constraints trailed at 15%. Three of the top four answers describe human-side or conceptual problems.

The pattern repeats inside the workflows themselves. Asked what makes human-AI collaboration hardest to run, practitioners pointed to two issues that came back almost in lockstep: recruiting people with the right domain expertise, and communicating tasks clearly enough for expert contributors to deliver against them. Cost again sat near the bottom.
This is what we mean by the calibration crisis. The signal AI teams need to steer modern models has become harder to find and harder to transfer than the industry's compute-first reflex prepared anyone for.
The role of the human in AI has quietly inverted
For most of the last decade, the phrase "human-in-the-loop" carried a fairly specific image. Large, anonymous crowds clicking through repetitive microtasks, drawing bounding boxes around cars in dashcam footage, tagging emails as spam or not spam, or choosing which of two model outputs sounded more natural. The work was high-volume, low-context, and largely interchangeable across the people doing it. Human intelligence functioned more or less as a raw input, purchased in bulk and fed into training runs that converted it into model behavior.
That mental model has not aged well.
When we asked practitioners which specific human contributions they rely on most, the top answer was designing evaluation methodologies, named by 47% of respondents. Subject matter expert validation followed not far behind. Both rank above the kinds of contributions that defined the previous decade of AI development: curating datasets, providing preference feedback, and creating ground truth labels. The work hasn't disappeared. It's been displaced from the center of the workflow.
This shift sounds technical, but the implications are organizational. Designing an evaluation methodology is not a task you can hand to a generalist, no matter how careful or well-paid. It requires someone who understands what the model is supposed to do well, where it tends to fail, and what kinds of edge cases would expose breakdowns that matter in deployment. A good evaluation methodology is, in effect, a theory of the model's intended behavior. The person writing it has to think adversarially about how that behavior could go wrong, and prescriptively about what success would look like in production. That's not annotation work. It's closer to test architecture.
The same logic applies to subject matter expert validation, which is showing up across an increasingly long list of vertical applications. Generalists can tell you whether a sentence is grammatical. They cannot tell you whether a legal argument cites the correct precedent, whether a clinical recommendation accounts for a relevant contraindication, or whether a block of code introduces a subtle security regression. As models start to take on tasks that require professional judgment, the only useful feedback comes from people who have the same professional judgment to give. The generalist annotator is being asked to step aside, not because the work has become harder, but because it has become specific in a way that defeats abstraction.
What this adds up to is a quiet inversion. In the old paradigm, engineers wrote the rules and humans executed against them. Today, in growing numbers of workflows, humans write the rules engineers are trying to teach the model to follow. The workforce sitting on the other side of these training pipelines is starting to look less like a labeler's pool and more like a network of architects, each shaping a small piece of the rubric the model will eventually be measured against.
This is the part of the calibration crisis that gets the least airtime. The work has changed, but the language and economics most teams use to describe their human pipelines have not caught up. That mismatch is where the next bottleneck shows up.
Why the budget can’t close this gap
The role change explains the bottleneck. When humans are designing the rubric, the instructions flowing from engineer to contributor have to carry far more than they used to. They need to convey how the model will eventually be deployed, what failure looks like in that deployment, and which edge cases the team is most worried about, even if those cases haven't appeared in the data yet. None of that compresses into a labeling guide written once and shipped to a queue.
This is the territory we covered in Business Reporter earlier this week, and the survey numbers underneath it sharpen the point. When we asked practitioners what slows their human workflows down, two challenges rose to the top together: finding people with the right combination of domain expertise and contextual understanding, and communicating tasks clearly enough that those people can actually deliver. Cost sat well below both. The friction has moved from procurement to translation.
That distinction is the heart of it. Engineers are no longer pushing instructions into a pipeline and getting outputs back. They're trying to convert tacit professional knowledge (the cardiologist's read on which arrhythmia patterns warrant escalation, the lawyer's instinct about whether a clause is unusually permissive) into explicit, repeatable evaluations. Most teams have not yet built any real infrastructure around that conversion. When it fails, the data still arrives. It just arrives noisier than anyone realizes, and noisy feedback compounds quietly into models that drift from their intended behavior over time.
Money does not fix translation. Operational maturity does. And operational maturity, on the human side of AI, is something almost no team currently has at scale.
What good calibration actually looks like
The teams pulling ahead on this aren't the ones spending more. They're the ones treating the management of human expertise as a first-class engineering problem, with the same operational rigor they apply to model architecture or deployment infrastructure. That looks like four things in practice, none of them glamorous.
The first is calibration before the task ever starts. Before a domain expert sees a single model output, the best teams invest serious time explaining what the model is being built to do, where it will be deployed, what failure looks like in that specific context, and which edge cases the engineering team is most worried about. A cardiologist evaluating a diagnostic model needs to know whether it's being built for triage in an emergency department or routine screening in primary care. Those are different tasks with different tolerances for different kinds of errors. Without that context, even the most qualified contributor is working in the dark, and the data they produce reflects it.
The second is treating feedback as a loop, not a transaction. Most teams write task instructions once, ship them to contributors, and treat whatever comes back as ground truth. That approach is a holdover from the labeling era, and it breaks the moment the work requires judgment. Mature human-AI workflows build in regular checkpoints where contributors flag ambiguous instructions, engineers tighten task design based on observed disagreements, and the gap between intent and interpretation gets smaller over time. The data quality improvement compounds. So does the model's.
The third is rethinking how expert recruitment works. Finding a credentialed expert is one thing. Finding a credentialed expert who can also translate their tacit professional knowledge into explicit, consistent evaluations is considerably harder, and it isn't a one-off procurement exercise. The teams getting this right have started treating it more like hiring than buying. Building relationships with domain networks, investing in contributor development, and creating the conditions for genuine expertise to be expressed rather than just extracted. We've written before about why domain expert access matters for the next generation of AI evaluation, and the survey data reinforces it. The expertise itself is increasingly available. The infrastructure for using it well is not.
The fourth is the budget question almost no one is asking out loud. Compute spend has scaled by orders of magnitude over the last three years. Spend on the human operations layer (the people, processes, and tooling that turn expert judgment into a reliable training signal) has not moved at remotely the same pace. That asymmetry is the real story for anyone making AI infrastructure decisions in 2026. The constraint on the next generation of models will not be GPU availability. It will be whether the teams operating those GPUs have built a human pipeline good enough to steer what they produce.
This is what the calibration crisis actually demands. Not more humans in the loop, but better infrastructure around the ones already there.
The bet and what it requires
The agent shift is no longer a forecast. 64% of the people building AI named autonomous systems as the area they expect to grow most over the next year, and the systems on the other side of that shift will be operating in healthcare workflows, financial transactions, legal review, and a long list of contexts where the cost of a confused output stops being conversational and starts being consequential.
What our 300+ practitioners are telling us is that the industry has not yet built the human infrastructure those systems will need to behave well. The signal that teaches a model to act with judgment has to come from people with judgment, communicated clearly enough to survive the trip from expert to engineer to model. Right now, in most teams, that pipeline is the weakest part of the stack. It is also the part that no amount of additional compute will repair.
The companies that ship agents people can actually trust in 2026 will be the ones that figured this out early. Not by hiring more annotators or signing larger data contracts, but by treating the human side of AI development with the same seriousness the rest of the field has reserved for model architecture and infrastructure. The calibration crisis is solvable. It just requires admitting that the bottleneck has moved and building accordingly.
We'll be publishing the full report later this year, with deeper segmentation by team maturity and AI domain, and a more detailed look at what the teams already operating ahead of the curve are doing differently.