HUMAINE: Understanding AI through human experience

Choosing the right AI model is no longer about finding the top score on a single benchmark. Today’s models excel in different ways, and understanding those differences matters for research, development, and real-world use.
HUMAINE is Prolific’s multi-dimensional AI leaderboard. It provides structured, human-centered feedback across multiple evaluation dimensions, helping researchers and builders understand how leading models actually perform, not just how they rank.
Instead of collapsing performance into one number, HUMAINE shows trade-offs. It highlights where models are strong, where they struggle, and how they compare across qualities that matter in practice.
Key insights at a glance:
- Model performance is not monolithic. Different evaluation dimensions surface different strengths, weaknesses, and levels of agreement among users.
- Some evaluation criteria are easier for people to judge decisively, while others show much higher levels of uncertainty or disagreement.
- Models vary in how consistently they are preferred across demographic groups, indicating that user characteristics can meaningfully influence evaluation outcomes.
- Demographic factors do not affect all models equally, highlighting the importance of looking beyond aggregate results.
HUMAINE is continuously updated as new models are released and evaluated. To see the latest results and current model comparisons, view the full ai leaderboard.
This post explains what HUMAINE is, why it exists, and how it helps researchers and AI practitioners evaluate and select models with greater confidence.
What is HUMAINE?
HUMAINE is Prolific’s multi-dimensional framework and leaderboard for evaluating large language models using human-centered feedback.
It measures how AI models perform across a set of distinct evaluation dimensions, rather than relying on a single aggregate score. This approach reflects how people actually experience and compare AI systems in real-world use.
HUMAINE is built on large-scale human evaluations. Participants compare model outputs and provide judgments across multiple criteria, generating rich preference data that reveals trade-offs, areas of consensus, and points of disagreement.
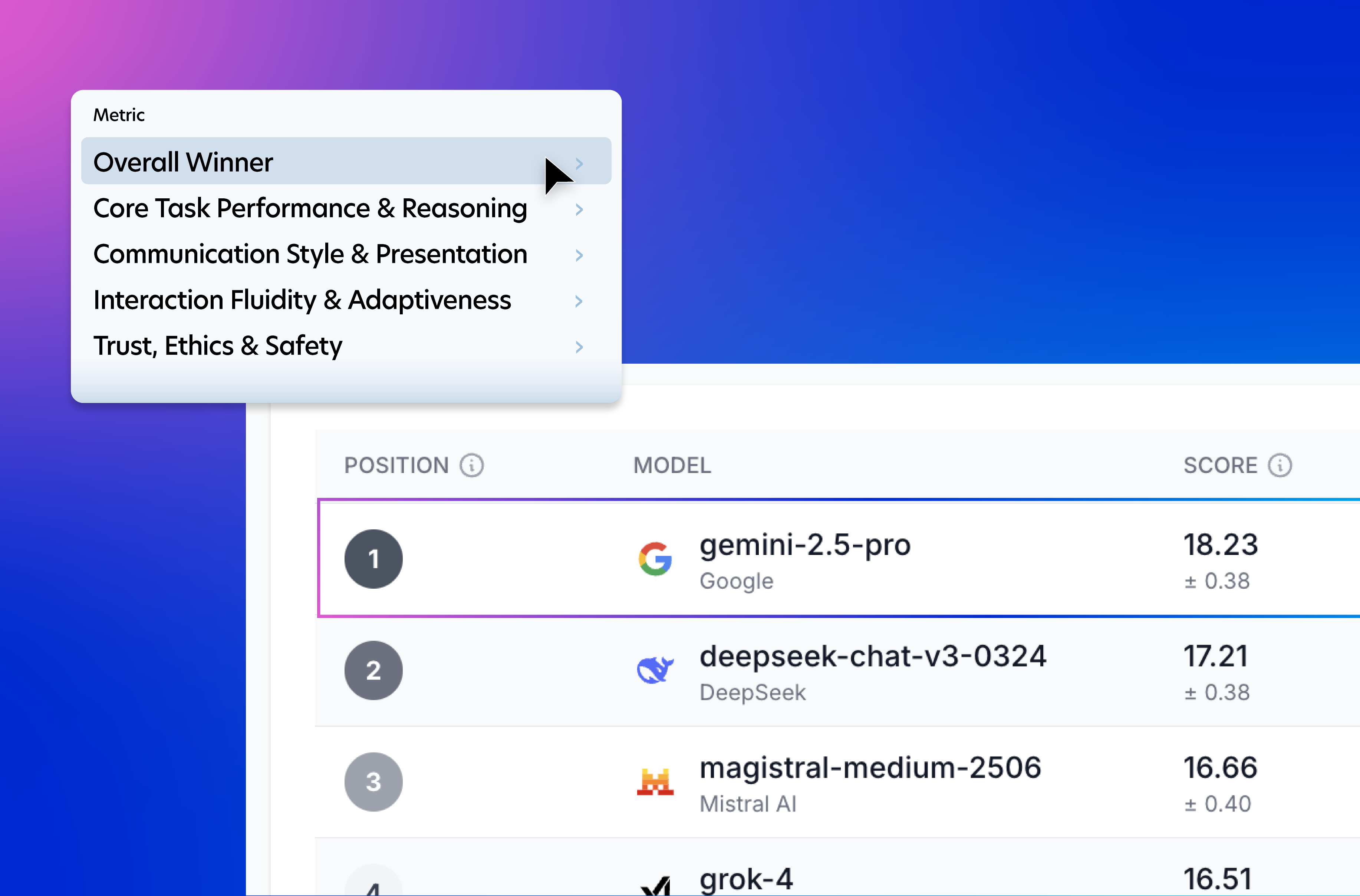
The results are presented as a leaderboard that shows how models perform across each dimension, as well as how consistently they are preferred across different groups of users. This makes it easier to understand not just which models perform well, but why they do, and for whom.
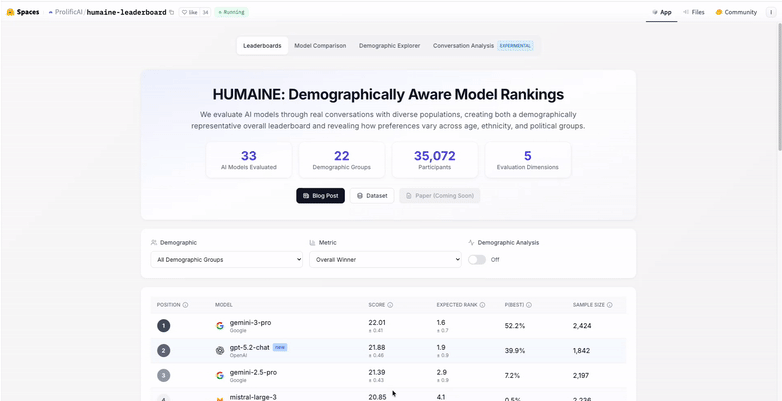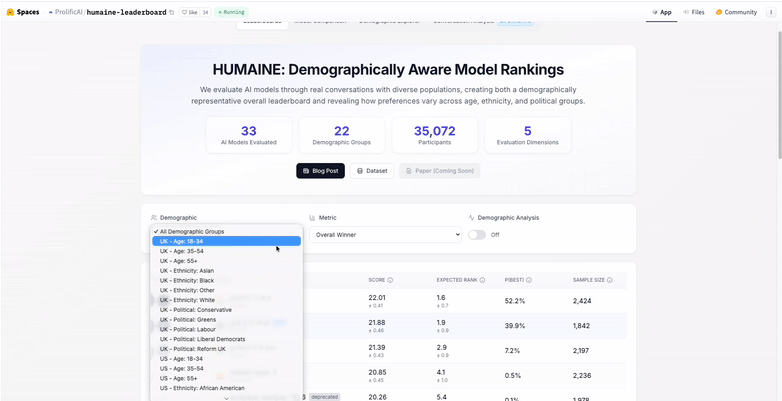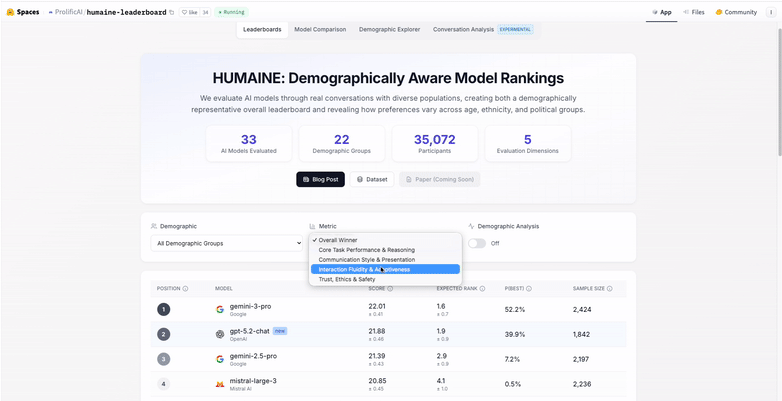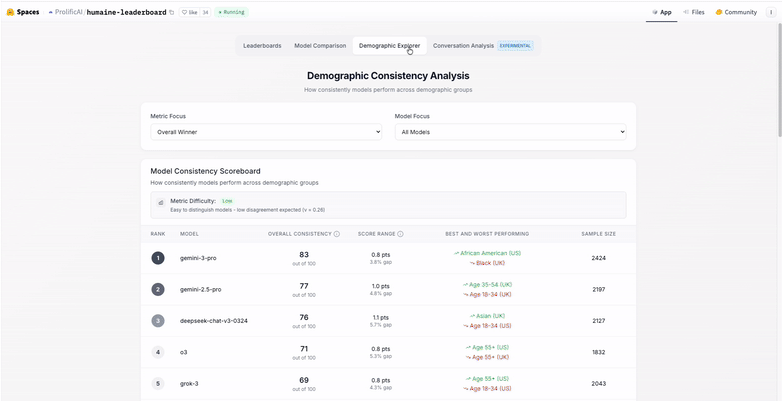
HUMAINE is designed to evolve. As new models are released and evaluated, the leaderboard updates to reflect the latest results, making it a living reference point for researchers and AI practitioners.
What do existing AI leaderboards miss?
Most AI leaderboards reduce model performance to a single score or rank. While this makes comparison simple, it also hides important differences in how models behave across tasks, users, and evaluation criteria.
In practice, AI performance is multi-dimensional. A model that performs well overall may still struggle in areas like reliability, safety, or user trust. Other models may excel in specific dimensions but appear weaker when results are collapsed into one number. Traditional leaderboards make these trade-offs hard to see.
HUMAINE addresses this gap by evaluating models across multiple human-centered dimensions. These dimensions reflect how people actually experience and judge AI systems in real interactions:
- Core task performance and reasoning: How effectively the model accomplished the user’s task and demonstrated sound reasoning and understanding.
- Interaction fluidity and adaptiveness: How smoothly and adaptively the model managed the conversation flow and responded to follow-up questions or changes in direction.
- Communication style and presentation: The quality of the model’s language, including tone, personality, clarity, and level of detail.
- Trust, ethics, and safety: The perceived reliability, transparency, ethical conduct, and safety of the model’s outputs and behavior.
Instead of asking which model is best in general, HUMAINE shows where models are preferred, where differences are subtle, and where user opinions diverge. This creates a more faithful picture of real-world performance and helps researchers and builders make decisions based on fit rather than rank alone.
Why does HUMAINE matter for AI researchers?
Evaluating AI models is no longer just a technical exercise. For researchers, it directly shapes study design, result interpretation, and the validity of downstream conclusions.
HUMAINE helps researchers move beyond narrow benchmarks by providing a structured view of how models perform across dimensions that align with human judgment. Instead of relying on a single score, researchers can see where models are consistently preferred, where differences are marginal, and where human evaluators disagree.
This matters when selecting models for experiments, comparing interventions, or interpreting behavioral outcomes. A model that performs strongly on core task execution may behave very differently when evaluated on communication style or trust-related criteria. HUMAINE makes these distinctions visible.
HUMAINE also surfaces variability across demographic groups. By showing how preferences differ by factors such as age, researchers can better understand whether a model’s performance is broadly robust or sensitive to user characteristics. This supports more transparent reporting and more careful generalization of results.
By grounding evaluation in large-scale human feedback and clearly defined dimensions, HUMAINE gives researchers a more reliable foundation for evaluating AI systems and for designing studies that reflect how people actually interact with them.
How does HUMAINE help people build on base models?
Choosing a base model is one of the most consequential decisions in building an AI system. That choice shapes product behavior, user experience, and the amount of effort required to fine-tune or control the model downstream.
For product teams and model builders, HUMAINE makes that decision more deliberate. Instead of defaulting to the highest-ranked or most talked-about model, teams can compare models based on the dimensions that matter most for their application.
For example, a team building an AI coding assistant may prioritize core task performance and reasoning. A team building a customer-facing chatbot may place more weight on interaction fluidity, communication style, and trust. HUMAINE allows teams to evaluate these dimensions directly, rather than assuming overall rank reflects suitability.
This dimensional view reduces costly trial and error. Instead of discovering limitations late in development, builders can use HUMAINE to identify likely strengths and risks earlier, before investing in customization, alignment work, or safety mitigations.
By making differences between base models visible and comparable, HUMAINE helps teams justify their model choice based on concrete performance characteristics, not reputation or momentum.
How can LLM users use HUMAINE to choose a model?
For LLM users, choosing a model often depends on the kind of experience they want to create. HUMAINE helps by making those differences visible before users commit to a model.
Instead of starting with overall rank, users can look at the evaluation dimensions that matter most for their use case. For example, applications that depend on accurate task completion and reasoning can prioritize models that perform strongly on core task performance. Products that involve extended conversations or frequent follow-ups may benefit from models that score well on interaction fluidity and adaptiveness.
HUMAINE is also useful when communication style matters. If tone, clarity, or the level of detail is important to the user experience, the communication style and presentation dimension provide a clearer signal than traditional benchmarks.
For use cases where trust, safety, or user confidence is critical, HUMAINE allows users to compare models based on how people perceive reliability and ethical behavior, not just raw capability.
Because HUMAINE is updated as new models are evaluated, users can revisit the leaderboard over time and adjust their choices as the model landscape changes. This makes it a practical reference for ongoing model selection, not a one-time decision.