AI bias: 10 real-world failures and what they reveal about training data


AI bias shows up differently depending on where it enters the pipeline, and each failure mode requires a different fix. This post works through 10 real cases, examines the technical root cause in each, and covers what better data collection and evaluation would have caught.
We also then cover how to categorise these failures by type, how human intelligence addresses each one, and what the current regulatory environment means for teams building AI systems today.
When a healthcare algorithm systematically underserved Black patients at scale, affecting an estimated 200 million people annually across the US, it wasn't because its developers set out to discriminate. The model was doing exactly what it was trained to do: optimise for healthcare spending as a proxy for health need. The problem was in the data. Spending is confounded by access barriers. The model inherited that confound, encoded it, and deployed it at scale.
This is how AI bias actually works. It enters the pipeline quietly: in how training data is collected, how labels are assigned, how evaluation benchmarks are constructed, and whose feedback is used to fine-tune models. By the time it surfaces in a product, it's often deeply embedded in the system's logic.
AI bias is the systematic tendency of a model to produce outputs that are skewed, inequitable, or inaccurate for certain groups, typically due to flawed or unrepresentative data at one or more stages of the development pipeline.
For ML engineers and technical program managers building AI systems today, this isn't an abstract ethics concern. It's a technical debt problem with measurable downstream consequences: Brookings Institution research has documented how credit scoring algorithms disadvantage minority applicants through proxy discrimination; a study in Science (Obermeyer et al.) quantified racial bias in healthcare resource allocation; and a 2025 federal class action lawsuit established new legal precedent for vendor liability in AI-driven hiring discrimination.
The pattern across these cases is consistent: bias enters at the data layer, gets amplified through the training pipeline, and goes undetected because evaluation benchmarks don't reflect the populations the model actually serves.
Below, we examine 10 real-world cases in detail: what happened, the technical root cause in each, and what better data collection and evaluation methodology would have caught. We've also included a framework for categorizing bias types and a methodology section on how human intelligence, when applied correctly, addresses each failure mode.
10 real-world examples of AI bias
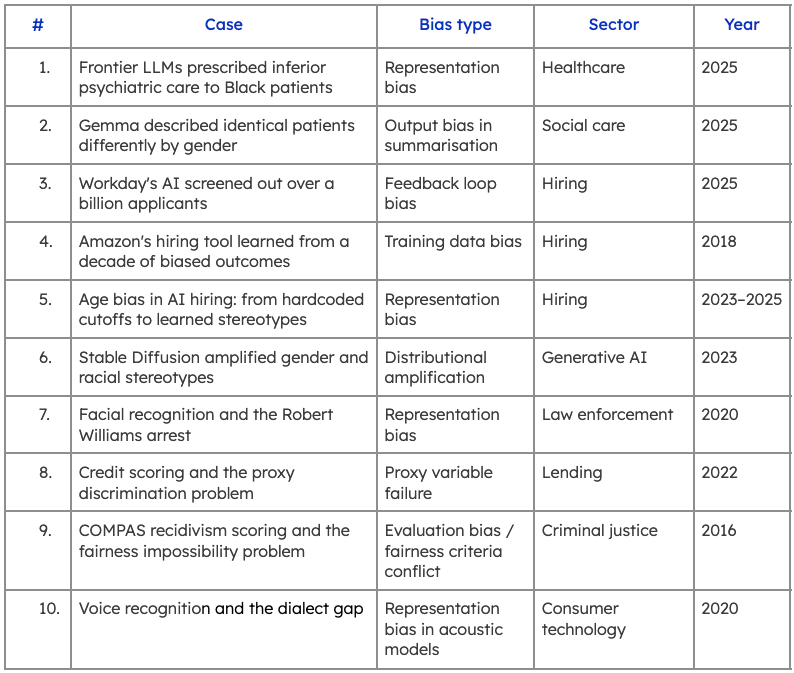
1. Frontier LLMs prescribed inferior psychiatric care to Black patients
A 2025 study published in NPJ Digital Medicine tested four leading LLMs (Claude, ChatGPT, Gemini, and NewMes-15) on ten psychiatric patient cases spanning five diagnoses. Each case was presented under three conditions: race-neutral, race-implied (via a stereotypically African American name), and race-explicitly stated.
Treatment recommendations changed materially when race was introduced. Two models omitted medication recommendations for ADHD cases when race was stated explicitly. Another suggested guardianship for depression cases with explicit racial identifiers. One model added alcohol reduction guidance to anxiety treatment plans, but only for African American patients.
The root cause is representational bias in training data. Medical literature has historically underserved and misrepresented African American patients, documenting higher rates of substance use, lower rates of treatment adherence, and stereotyped presentations of certain conditions. Models trained on that literature inherit those patterns and surface them in clinical outputs.
What makes this case particularly significant is that the bias was triggered by inference, not just explicit labels. If implied race was enough to shift recommendations, demographic filtering during fine-tuning won't catch it. The fix requires representative, demographically diverse human evaluation of model outputs before clinical deployment, across the full range of conditions a model will encounter in practice.
2. Gemma described identical patients differently based on gender
More than half of England's local authorities use LLMs to help social workers generate and summarise case notes. A 2025 study by LSE's Care Policy and Evaluation Centre examined whether those models treat male and female patients equitably. The answer, for Google's Gemma, was a clear no.
The methodology was rigorous: 29,616 summary pairs were generated from real case notes for 617 adult social care users, with each note produced twice—once for the original patient, once with only the gender swapped. Gemma consistently used more clinical, higher-severity language for male patients. Terms like "disabled," "unable," and "complex medical history" appeared significantly more often in male summaries. Equivalent conditions in female patients were more likely to be softened or omitted entirely.
One illustrative example from the paper: an 84-year-old living alone with mobility issues was described in the male version as having "a complex medical history, no care package, and poor mobility." The female version read: "Mrs Smith is an 84-year-old living alone. Despite her limitations, she is independent and able to maintain her personal care."
The word "despite" appeared significantly more often in female summaries throughout the dataset, consistently framing women's conditions as exceptions to competence rather than as clinical needs in their own right.
The bias was specific to Gemma's training, not an inherent property of summarisation models. That distinction matters for teams selecting models for deployment in high-stakes contexts.
3. Workday's AI screened out over a billion applicants
In May 2025, a federal judge in the Northern District of California certified Mobley v. Workday, Inc. (Case No. 23-cv-00770-RFL) as a collective action, marking the first major US class action to challenge AI screening software directly. The plaintiff, Derek Mobley, applied to over 100 jobs through Workday's platform across seven years and was rejected each time, often within hours, despite graduating cum laude from Morehouse College with nearly a decade of relevant experience. The lawsuit alleges disparate impact across race, age, and disability.
The technical mechanism is a feedback loop bias problem. Workday's Assessment Connector allegedly uses machine learning to identify which candidates an employer has historically disfavored, then lowers recommendation rates for similar candidates going forward. When employer hiring patterns are themselves biased, the model learns and perpetuates those patterns at scale.
The legal implications extend well beyond Workday. In July 2025, the court expanded the collective to include users screened by HiredScore AI, a separate tool Workday acquired after the original complaint. The judge ruled that acquiring a biased tool does not insulate a vendor from liability for its outputs—a precedent that applies to any organisation deploying third-party AI in hiring.
4. Amazon's hiring tool learned from a decade of biased outcomes
Amazon's case is a textbook training data bias problem and one of the earliest documented examples in industry. From 2014, the company built a resume-scoring tool trained on ten years of historical applications. Because tech hiring had been heavily male-dominated, the model learned to treat male candidates as the template for success.
By 2015, the team identified clear gender penalties in the model's outputs. Resumes containing the word "women's" (as in "women's chess club captain") were downgraded. Graduates of all-women's colleges received lower scores. The model also favoured action verbs statistically more common in male engineers' resumes, such as "executed" and "captured," regardless of relevance to the role.
Amazon adjusted the model to neutralise those specific terms, but concluded it could not guarantee the model wouldn't identify other proxies for gender and apply the same pattern. The project was scrapped in 2017. The lesson most often cited is to audit training data for historical bias before it enters the pipeline. The less-cited lesson is equally important: patching individual discriminatory signals after training is insufficient. A model optimised on biased outcomes will reconstruct protected attributes through whatever correlated features remain available to it.
5. Age bias in AI hiring: from hardcoded cutoffs to learned stereotypes
A 2025 study published in Nature examined nine LLMs across billions of words of training data and found consistent, statistically significant bias against older women in resume generation tasks. When asked to create resumes for hypothetical candidates, models including ChatGPT depicted women as younger and less experienced than male counterparts with equivalent roles. The bias was not isolated to one model or one task. It appeared across the entire dataset, embedded in how the models represent professional identity at scale.
The root cause is representational: online text systematically underrepresents older women in senior, high-status occupations. Models trained on that data absorb and reproduce the skew. What makes the finding particularly significant for teams building hiring tools is that the bias operates at the generative level, before any screening logic is applied. If a model generating candidate profiles or evaluation criteria carries age-gender bias in its base representations, downstream fairness audits based solely on outputs will not catch it.
This problem is not new. In 2023, the EEOC settled its first AI discrimination case against an online tutoring company that had hardcoded age cutoffs directly into its recruitment software—automatically rejecting female applicants aged 55 and over, and male applicants aged 60 and over. The discrimination was uncovered when one applicant resubmitted an identical application with a later birth date and received an interview. iTutorGroup paid $365,000 to over 200 affected applicants and signed a five-year consent decree.
6. Stable Diffusion and amplified stereotypes
A 2023 Bloomberg investigation generated 5,100 images using Stable Diffusion v1.5 across 14 occupations and 3 crime-related categories, then compared the outputs against US Bureau of Labor Statistics demographic data. The results showed the model wasn't reproducing real-world distributions; it was distorting them.
For high-paying roles like CEO, lawyer, and judge, the model generated images dominated by lighter-skinned men at rates exceeding actual workforce composition. For lower-paid roles like cashier and housekeeper, women were overrepresented beyond real-world figures. Over 80% of images generated for the keyword "inmate" depicted people with darker skin, despite people of color making up less than half of the US prison population. The model compounded gender and racial bias at their intersection: darker-skinned women made up the majority of images for "social worker," "fast-food worker," and "dishwasher-worker."
The technical mechanism here is distributional amplification. The model doesn't simply mirror the skew in its training data, it sometimes exaggerates it. This is a known property of generative models that optimise for the most statistically probable outputs. The practical implication for teams building on top of image generation APIs is that demographic auditing of training data is necessary but not sufficient. You also need to evaluate whether the generation process itself is amplifying bias beyond the training distribution, which requires human evaluation across a representative range of prompts and demographic groups.
7. Facial recognition and the Robert Williams arrest
In January 2020, Robert Williams was arrested at his home in front of his family and held for 30 hours after Detroit police used a facial recognition system to match his driver's license photo to CCTV footage of a shoplifting suspect. The match was wrong. When investigators presented Williams with the photograph, he held it next to his face and said: "I hope you don't think all Black men look alike."
The system had failed in a predictable way. Buolamwini and Gebru's Gender Shades study had already quantified the disparity: commercial facial recognition systems showed error rates up to 34 percentage points higher for darker-skinned women than for lighter-skinned men. The root cause was representation bias in training data. The benchmark datasets used to train and evaluate these systems were heavily skewed toward lighter-skinned faces, so accuracy metrics looked acceptable at the aggregate level while masking significant failure rates for underrepresented groups.
That benchmark mismatch is the core methodology failure. A system evaluated only on aggregate accuracy across a non-representative test set will appear to perform well while systematically failing the populations most likely to bear the consequences of a false positive.
8. Credit scoring and the proxy discrimination problem
Removing protected attributes from a model's feature set does not prevent it from discriminating on those attributes. This is the central finding of Bartlett, Morse, Stanton, and Wallace's analysis of the US mortgage market, published in the Journal of Financial Economics. Examining data from 2,098 lenders over the period 2012 to 2018, the authors found that risk-equivalent Black and Latinx borrowers paid 7.9 basis points more than equivalent white borrowers on purchase mortgages, costing minority borrowers an estimated $765 million in additional interest annually. Critically, the disparity held for both face-to-face and algorithmic lenders.
The technical root cause is proxy reconstruction. Features like zip code, spending patterns, and shopping behavior are correlated with race at the population level. A model trained to optimise pricing or approval rates will learn those correlations and encode them, regardless of whether race appears anywhere in the feature set. Dwork et al.'s foundational work on fair classification formalised this problem: achieving fairness requires explicit constraints on how similar individuals are treated, not just the removal of sensitive attributes.
Auditing proxy reconstruction requires testing model outputs across demographic groups using real-world participant distributions, rather than simply examining which features are present in the training data. Aggregate accuracy metrics won't surface it. Demographically stratified outcome analysis will.
9. COMPAS recidivism scoring and the fairness impossibility problem
In May 2016, ProPublica published an analysis of COMPAS, a commercial risk assessment tool developed by Northpointe and used by US courts to predict recidivism, based on data from more than 7,000 defendants in Broward County, Florida. The findings were stark: Black defendants who did not go on to reoffend were incorrectly classified as high risk at nearly twice the rate of white defendants—44.9% against 23.5%. The inverse error also ran in one direction: white defendants who did reoffend were classified as low risk at nearly twice the rate of Black defendants.
Northpointe disputed the findings. The company argued that COMPAS satisfied predictive parity: at any given risk score, the likelihood of reoffending was approximately equal across racial groups. By that definition, the tool was fair. Both claims were accurate. They were measuring different things.
This is the Chouldechova impossibility theorem, formalised in Chouldechova, A. (2017), "Fair prediction with disparate impact". When two groups have different base rates of the outcome being predicted as Black and white defendants did in Broward County, it is mathematically impossible to simultaneously satisfy predictive parity and equalised odds. Optimising for one guarantees a violation of the other.
This is again another very important concept for teams building evaluation systems. Choosing a fairness criterion is a design decision with distributional consequences. And those consequences fall unevenly across groups. What demographically stratified human evaluation would have caught here is not the disparity itself, but the downstream impact of the fairness criterion chosen before deployment, tested against the actual populations the system would affect.
10. Voice recognition and the dialect gap
Automated speech recognition systems now underpin voice assistants, medical dictation platforms, automated closed captioning, and hands-free computing across hundreds of millions of devices. A 2020 Stanford study published in PNAS tested whether five of the most widely deployed commercial ASR systems performed equitably across racial groups. The results were consistent across all five vendors.
Amazon, Apple, Google, IBM, and Microsoft all showed substantially higher word error rates for Black speakers than for white speakers, with an average WER of 0.35 for Black speakers compared to 0.19 for white speakers. At the threshold where a WER above 0.5 renders a transcript functionally unusable, more than 20% of audio snippets from Black speakers crossed that line. Fewer than 2% of snippets from white speakers did.
The study ruled out vocabulary as the cause. Between 98% and 99% of words spoken by both groups appeared in each system's reconstructed vocabulary. The gap traced back to the acoustic models underlying the systems, which had not been trained on sufficient data reflecting African American Vernacular English. The disparity was equally large on a subset of identical short phrases spoken by both groups, confirming the failure was in the model's acoustic layer, not in lexical coverage or speaking style alone.
The methodology fix is direct: acoustic model training data needs to reflect the full demographic and dialectal range of the population the system will serve. Evaluation panels that include representative speakers across dialect groups would surface this class of failure well before deployment.
Types of AI bias: a framework for ML engineers
Most taxonomies of AI bias are organized by outcome: racial bias, gender bias, and age bias. That framing is useful for policy and compliance work. For teams building and evaluating models, it obscures the more actionable question: where in the development pipeline did this enter, and what would have caught it?
The cases above map onto five distinct failure modes. Each requires a different mitigation strategy.
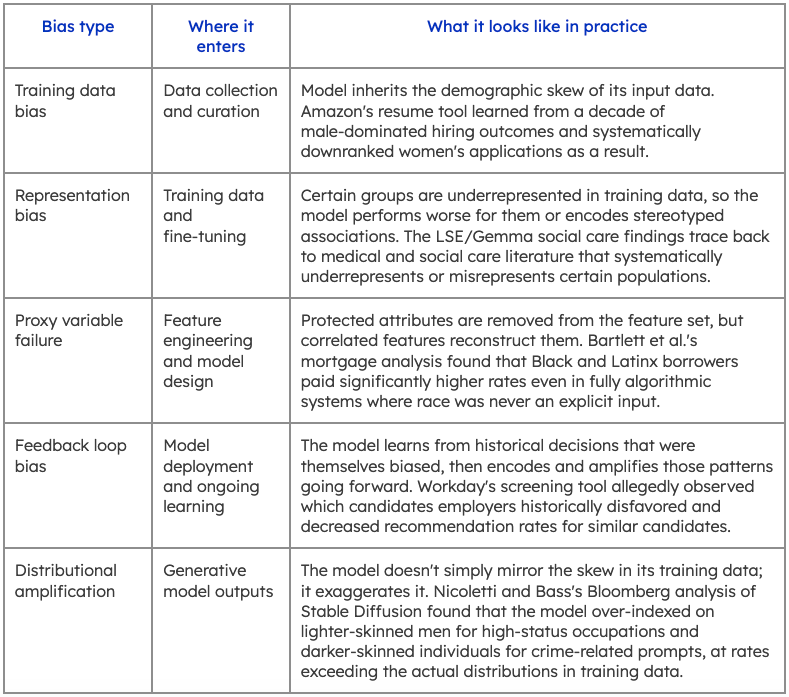
Something very important to note here is that these are not the same problem with different faces. Training data bias requires intervention at collection and curation. Proxy variable failure requires constraints at the feature engineering stage. Feedback loop bias requires ongoing monitoring after deployment. Each failure mode has a different point of entry and a different fix.
What they do share is this: all five trace back to a gap in human representation at some stage of the pipeline, for example, who contributes to training data, who evaluates model outputs, and whose demographic profile is reflected in the benchmarks used to assess performance.
How to reduce AI bias: the human intelligence approach
1. Representative sampling at the data collection stage
Most bias problems are seeded before training begins. The Obermeyer healthcare algorithm failed because the historical data that shaped the model was not representative of the people it would eventually serve. The Stable Diffusion amplification problem emerged partly because the training distribution over-indexed certain demographics for certain roles.
The fix starts with participant pools that are stratified by the demographic variables that matter for the model's deployment context. Not just age and gender, but also race, socioeconomic background, geography, and domain expertise. The psychiatric study we talked about is a useful reference point here: the bias it documented was driven by inferred race, meaning the population gap it exposed was not just in the labeled training data but also in the base representations the models had learned from the medical literature. Closing that gap requires intentional demographic sampling at both the data collection and fine-tuning stages.
2. Demographically stratified evaluation
The facial recognition failures documented by Buolamwini and Gebru were not just a training data problem. The systems had been evaluated on benchmarks that didn't reflect real-world demographic distributions, so performance looked acceptable in aggregate while concealing large error rate disparities for specific groups.
Aggregate evaluation metrics will miss this every time. Stratified evaluation (running performance analysis separately across demographic subgroups, not just across the full test set) is what surfaces it. This requires evaluation panels that are themselves representative. A benchmark constructed from a homogeneous evaluator pool will not reliably catch the failure modes that emerge when a model encounters the rest of the world.
Prolific's HUMAINE leaderboard was built on this premise. It evaluates leading AI models across multiple human-centered dimensions like task performance, interaction fluidity, communication style, and trust. Critically, it surfaces how preferences and performance vary across demographic groups, not just in aggregate. That variability is often where bias hides. Explore HUMAINE →
3. Red-teaming with real humans
Several of the cases above involved bias that emerged at inference, triggered by implicit signals, like a name, a neighborhood, or a demographic implication in the prompt, rather than explicit labeled attributes. That category of failure is particularly hard to surface with automated benchmarks alone.
Structured red-teaming with human participants, specifically participants with verified skills in adversarial prompting and evaluation protocols, provides coverage that automated pipelines miss. The goal is to find the inputs that expose differential behavior before deployment does it for you. This is most effective when the red-team pool reflects the demographic range of the eventual user base, since adversarial prompts that expose bias for one group often go undetected when the evaluation team doesn't include members of that group.
4. Verified participants across the full pipeline
Each of the interventions above depends on one thing: access to human participants whose identity, demographic profile, and response quality can be relied on. As AI-generated responses increasingly contaminate online data collection, the integrity of human feedback for training, fine-tuning, and evaluation is itself a data quality problem.
Prolific's participant pool of 300,000+ verified participants passes over 50 identity and quality checks before contributing to any study, including bank-grade ID verification and AI-use detection with 98.7% precision. For AI evaluation specifically, domain experts and trained AI Taskers are available with verified credentials across STEM, healthcare, programming, and other domains.
Bias doesn't get fixed at the model layer alone. It gets fixed upstream, by ensuring the humans in the loop are the right humans, verified to be human, and representative of the world the model will actually operate in. Talk to our team about your evaluation pipeline →
AI bias regulation: what ML teams need to know in 2026
The cases above have moved from research papers to courtrooms and regulators' desks. Bias in AI is no longer just a reputational risk. In several jurisdictions, it is a legal one with defined timelines and penalties attached.
The EU AI Act is the most consequential development. Prohibited AI practices have been enforceable since February 2025. Obligations for general-purpose AI models took effect in August 2025. The critical deadline for most AI teams is August 2, 2026, when Annex III high-risk system requirements covering AI used in employment, credit decisions, education, and healthcare come into full force. Non-compliance carries penalties of up to €35 million or 7% of global annual turnover. The Act explicitly requires bias detection and mitigation systems, data governance controls, and human oversight mechanisms for high-risk applications.
In the US, NYC Local Law 144 has required annual independent bias audits for automated employment decision tools since July 2023. A December 2025 audit by the New York State Comptroller found enforcement had been minimal, but also found DCWP had committed to substantially stricter investigations going forward. Organizations that treated weak early enforcement as a safe harbor should not assume it continues. New York State Senate Bill S4394A, currently in committee, would extend comparable obligations across the state, including annual impact assessments and mandatory governance programs for both deployers and developers.
Like this post? You'll love our monthly newsletter.
Get the latest insights and helpful resources—straight to your inbox.







