Why the researchers at Cohere and Princeton think AI learns by forgetting


From The Frontier Series, Episode 4. Henry Conklin (Cohere / Princeton) and Tom Hosking (Cohere) in conversation with Nora Petrova and John Burden, Prolific research engineers. Recorded at ICLR, Rio.
LLM interpretability has become one of the most active areas in AI research. Since 2023, researchers have published over 18,000 papers trying to understand what happens inside large language models, but a harder question remains largely unanswered: do any of these findings tell us how models actually learn? Knowing which feature activates when doesn't explain whether a model has genuinely understood a concept or simply memorized a pattern.
On the latest episode of the Frontier Series, Prolific's research podcast featuring conversations with researchers at the frontier of AI, hosted by Prolific researchers Nora Petrova and John Burden, Henry Conklin and Tom Hosking came with a different way of framing the problem. Conklin is a postdoctoral research fellow at the Princeton AI Lab and a researcher at Cohere; Hosking is a member of technical staff at Cohere working on model merging and LLM development. "You would hope that means we have an 18,000-times better understanding of how LLMs work," Conklin said of the interpretability literature. "But I don't necessarily know that's the case."
Their paper, "Learning is Forgetting: LLM Training as Lossy Compression," presented at ICLR 2026, argues that the most useful way to understand how AI learns might be to think carefully about what it forgets. Listen to more of their conversation:
Learning is forgetting: what that actually means
Henry and Tom argue that the best way to understand how LLMs learn is to look at them through the lens of compression. "Learning in the general case, when it goes well, is an act of compression," Conklin explains. To make that idea concrete, they reach for an analogy from everyday life.
Think about how an MP3 works. A raw audio file is enormous. An MP3 dramatically reduces its size by discarding information that humans aren't able to perceive anyway. Our hearing has a finite range of frequencies, so an MP3 strips out the rest and the song still sounds like the song. JPEGs work the same way: subtle color variations that human eyes can't detect get removed, and the picture still looks like the picture. In both cases, something is thrown away, and the result is better for it.
An LLM's raw data is the entire internet and every digitized book ever written. Conklin and Hosking argue it doesn't need to retain a complete lookup table of everything it has seen to produce accurate, useful answers. What it needs to do is compress: find what's invariant and genuinely meaningful, and discard the rest.
If a model holds on to too much, it fails to learn anything at all. Henry offers an analogy: Imagine someone teaches you to make an omelet. They use a red bowl, crack eggs into it, whisk them with a fork, and put them in a pan. If you memorize that exact sequence, you've retained everything and learned nothing. The next time you see a blue bowl, you'll think: that's not an omelet. A whisk instead of a fork? Not an omelet. "By retaining all the information, you have failed to learn the concept," Henry explained. The inverse is also true: if you compress too far and conclude that an omelet is simply "eggs in a pan," you've lost too much to reconstruct what you were supposed to learn.
Good learning sits precisely between those two failures. It forgets the irrelevant specifics and retains only the abstraction that generalizes.
The researchers tested this across 75 open-weights models from a range of providers, finding that how optimally compressed a model is significantly predicts downstream performance across 47 of them. Strikingly, models from different providers, trained on different data with different recipes, all converge toward the same bound on optimal compression, though what each model retains within that compression differs depending on how it was built.
The "7": what it looks like when learning goes right
Henry and Tom wanted to see what compression looks like in practice: to plot the trajectory of a model actually learning, checkpoint by checkpoint, across all of pre-training.
They used a mathematical framework called the Information Bottleneck Theory, a framework introduced in the late 1990s and applied to deep learning around 2015, which describes training as a compression of the data the model sees. The framework lets you track two things: how much information from the input the model retains (its complexity) and how well the model can reconstruct its goal from those retained representations (its expressivity). Plot both over time and you get a picture of how learning unfolds.
For a 7-billion-parameter model, they calculated these values across all available training checkpoints, feeding in 10,000 samples from C4, a broad crawl of internet text, to get a reliable estimate at each stage. Then they plotted it.
"It was a very clean line," Henry said. In the first phase of training, complexity and expressivity both rise: the model absorbs information and learns to do the task. In the second phase, complexity starts to fall while expressivity stays broadly stable. The model reorganizes, discards what doesn't matter, and approaches an optimal bound. Plotted in two dimensions, the trajectory traces a shape.
"I texted Tom a screenshot and said, 'Oh my god, we have a 7!'"
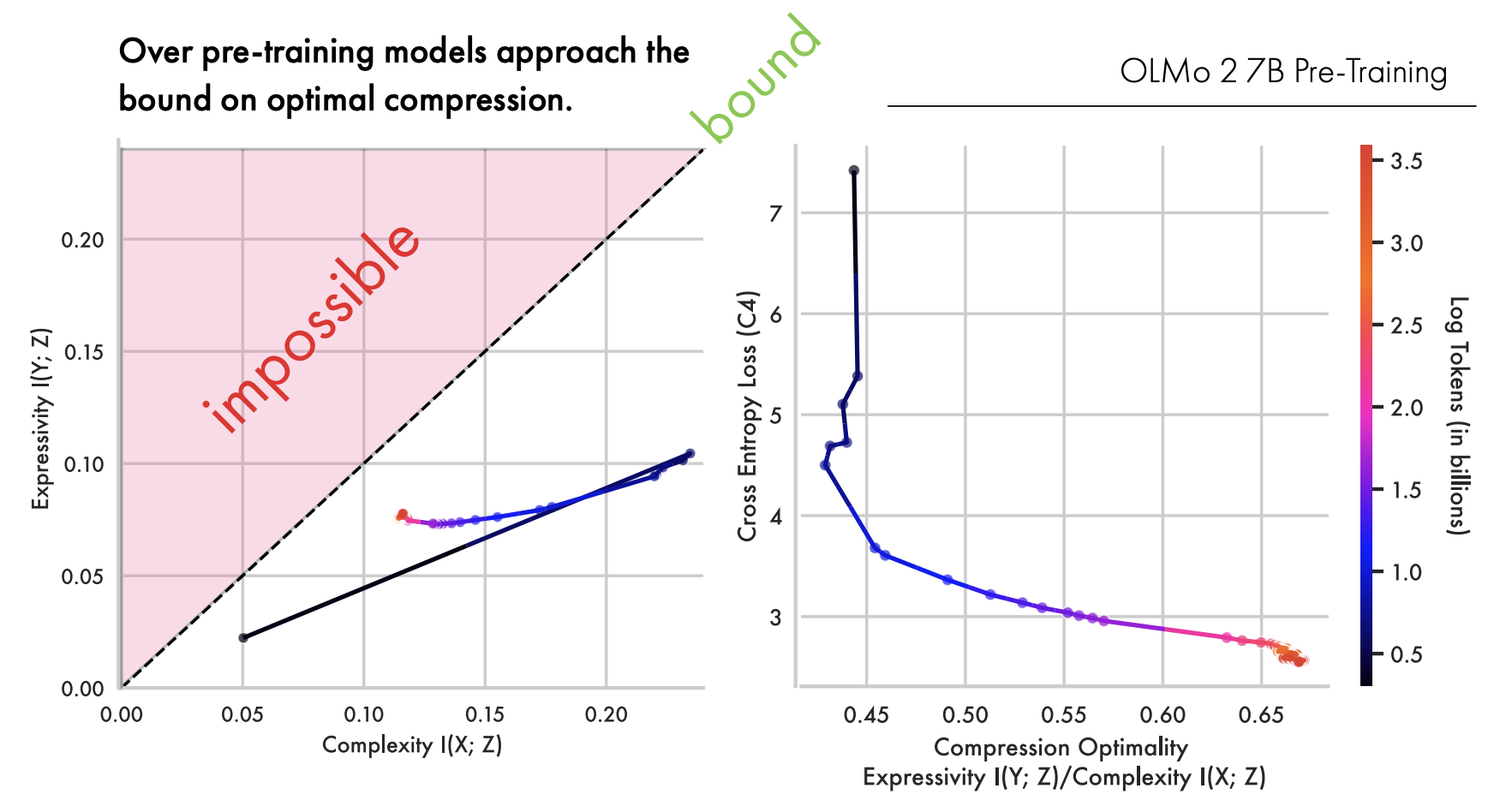
The information plane for OLMo2 7B over pre-training. The trajectory traces the two-phase compression path Conklin and Hosking describe as the signature of learning going well. Figure 1 from 'Learning is Forgetting: LLM Training as Lossy Compression' (Conklin et al., ICLR 2026).
That shape is an identifiable signature of learning going well, of data complexity and model capacity being genuinely well-matched. When that alignment breaks down, the trajectory breaks down too. The researchers looked at a 1-billion-parameter model trained on 4 trillion tokens, far more data than a model that size can meaningfully hold, and watched it oscillate, doubling back on itself, unable to settle on a stable compression. It never produced the clean "7." The pattern confirmed something practitioners had known anecdotally for years: below around 7 billion parameters, model performance drops off in a meaningful way. Now there's a theoretical account for why.
Why behavior is a bad proxy for understanding
The standard way to assess whether a model is good is to test its behavior: run it against benchmarks, measure its outputs, score it on tasks. Behavior tells you very little about what a model has actually learned.
Tom put it plainly: "Evaluating how a model behaves doesn't tell you how it's actually working. Behavior doesn't necessarily tell you about representational structure."
Consider what that means in practice. Imagine you have 100 model candidates that all score identically on your benchmarks. You have to believe some are better than others, but you have no way of seeing why. And if evaluation data accidentally gets mixed into training, which has happened with prominent benchmarks, a model can score beautifully while having learned almost nothing transferable. "The model will look beautiful on the benchmark," Henry said, "but that isn't indicative of meaningful robustness."
The compression framework offers an alternative. Instead of asking what a model outputs, ask what geometry its internal representations have. The more optimally compressed a model's structure, the more likely it is to be genuinely robust rather than just well-optimized for the specific tasks it has been evaluated on. A model with good internal geometry may outperform a larger model on real-world tasks even when it scores lower on benchmarks. The researchers found exactly that: some smaller models can punch above their weight when they have rich information about what makes for a good answer, built up through post-training, even if their pre-training compression is suboptimal.
Henry was direct about the broader problem: "Behavior is a bad proxy for whether a model has meaningfully learned something."
What this means for research
Tom and Henry's framework measures internal representational structure to identify models likely to generalize robustly, rather than models that have simply been well-optimized for evaluation. Their next work applies the same lens to post-training: the reinforcement learning, fine-tuning, and preference alignment steps that happen after pre-training, and which nobody yet has a clean theoretical account of. What those processes actually do to a model's information structure is an open question with real consequences for systems being deployed right now.
For most researchers working with AI systems they can't look inside, the question becomes more practical: how do you get reliable signal about what a model has actually learned when you can only observe its outputs?
Human judgment doesn't replace technical evaluation, but it reaches places benchmarks can't. Humans encounter models in the full complexity of real use, with contextual knowledge, subjective experience, and fine-grained judgment that behavioral scores don't capture. When models converge on benchmark performance, that's precisely when human signal becomes the more informative differentiator.
Henry Conklin and Tom Hosking joined Prolific's research engineers Nora Petrova and John Burden for Episode 4 of the Frontier Series. Watch the full conversation and read the paper, "Learning is Forgetting: LLM Training as Lossy Compression."





