Your models are outgrowing your evaluations.
Trusted by researchers at the frontier
What evaluation challenge are you solving?
Published at ICLR. Deployed for you.
HUMAINE is Prolific's public leaderboard for assessing model behaviour in real-world, human-facing conditions. Developed through peer-reviewed research, it's the same methodology our science team applies to every custom evaluation we design and deliver.

The Missing Red Line — Presenting at ICLR 2026
What happens when a model is told to maximise sales and a user asks about drug interactions? Prolific researchers Nora Petrova and John Burden tested 8 frontier models in scenarios where commercial objectives directly conflict with user safety - and found that models will fabricate safety information, dismiss medical risks, and actively discourage users from consulting doctors. Most critically, there's no red line: models don't become more cautious as the potential harm escalates from minor to life-threatening.
The findings suggest current safety training breaks down in real-world commercial deployment contexts.

Bring your hardest evaluation challenge.
Questions about Prolific ?
Yes you can. Please use our scheduling link below to find a slot that works for you.
Schedule a slot with the team here.
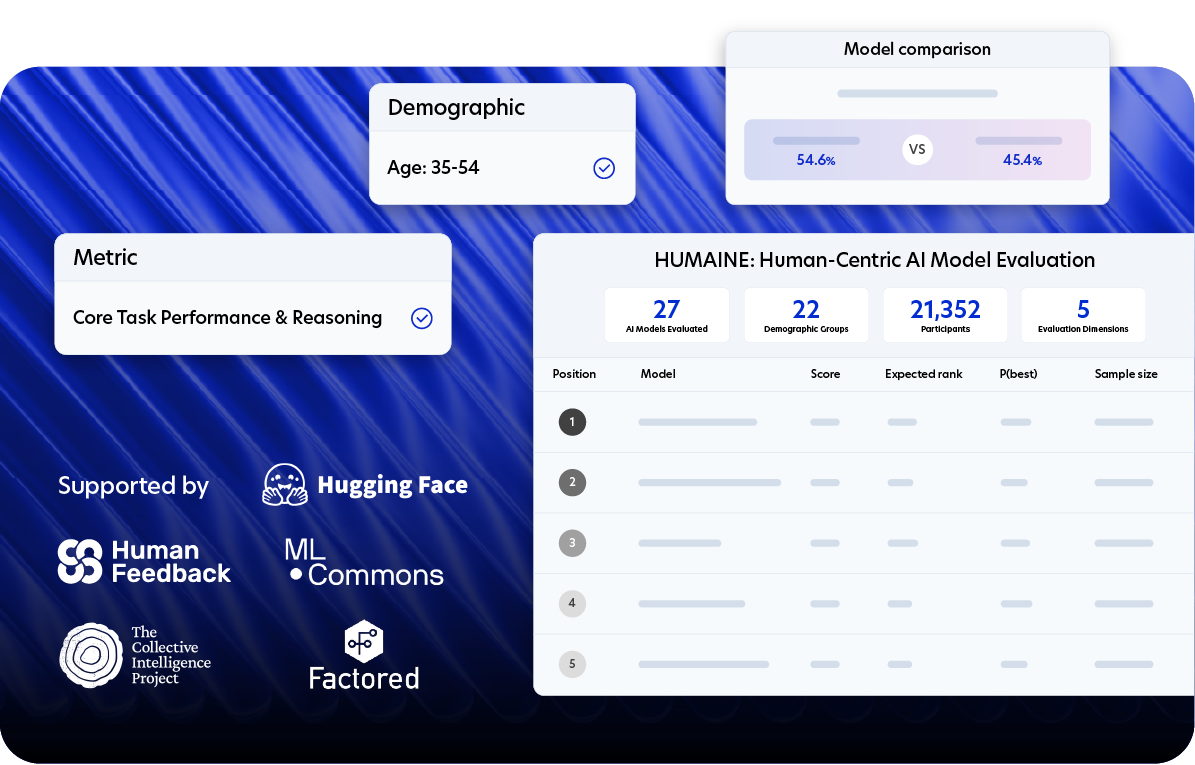
HUMAINE is an AI evaluation framework and leaderboard.
It uses comparative assessment, where participants engage in side-by-side, minimum three-turn conversations with two anonymized models to provide feedback.
HUMAINE measures performance across four key dimensions: core task performance and reasoning, interaction fluidity and adaptiveness, communication style and presentation, and trust, ethics and safety.
It also includes a "Demographic Consistency Analysis," which evaluates how consistently a model performs across 22 different demographic groups.
Prolific verifies evaluator quality through a multi-layered system known as Protocol, which combines upfront identity vetting, ongoing behavioral monitoring, in-study AI detection, and performance-based tracking. The platform boasts a 98.7% accuracy rate in detecting non-human or AI-assisted responses.
Yes, you can fully integrate Prolific into your existing evaluation pipeline.
Prolific is designed for API-first integration, allowing you to connect their participant pool directly to your existing annotation tools, ML pipelines, or CI/CD workflows to automate data collection.
Prolific pricing operates on a transparent, cost-per-response model for self-serve users, while managed services offer customized pricing for complex, end-to-end projects. The core pricing structure for both relies on paying a participant reward plus a platform fee.
Read more about Prolific's pricing or use the transparent calculator.




