HUMAINE: the human-centered AI leaderboard
In partnership with


Beyond Technical Evals: Why Human-Centered AI Benchmarks Matter
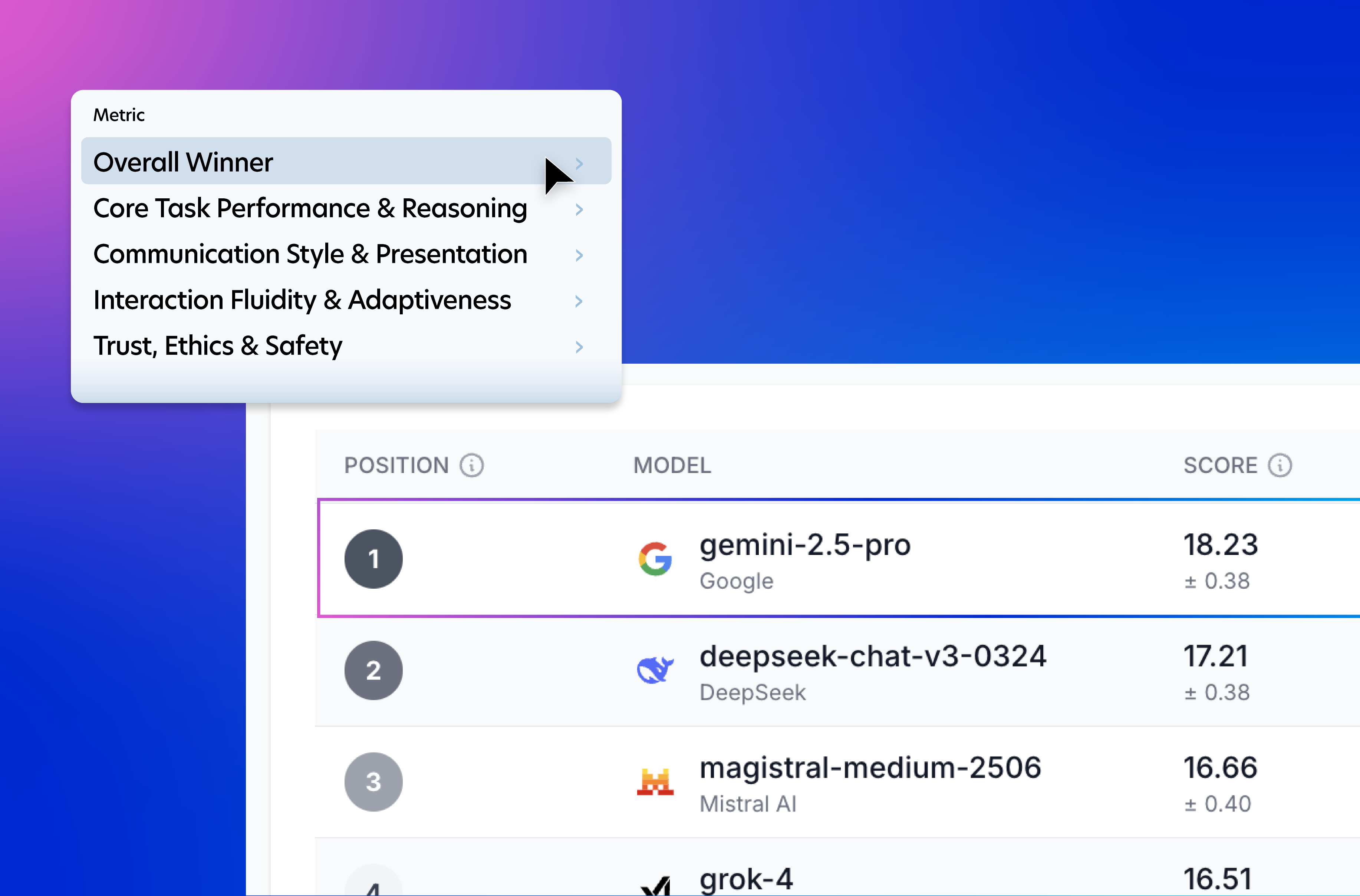
HUMAINE is a human-preference leaderboard that evaluates frontier AI models based on real-world usage. Unlike traditional benchmarks that mainly track technical performance, HUMAINE captures how diverse users actually experience AI—across everyday tasks, trust and safety, adaptability, and more.
By combining rigorous methodology with feedback from a representative pool of real people, HUMAINE offers the insights model creators and evaluators need to understand not just which model performs best, but why. Updated regularly, it provides a dynamic view of model strengths, weaknesses, and user satisfaction.
Explore the leaderboard
HUMAINE AI Leaderboard FAQs
HUMAINE is designed for AI labs, model creators, and evaluators who want to understand how their models perform in real-world contexts. It’s also useful for researchers, policy makers, and practitioners interested in human-centered AI evaluation.
Yes, the HUMAINE Framework (Human-Centered LLM Evaluation) is a published. It was featured as a conference paper at ICLR 2026.
Read the paper on ArXiv.
Results are refreshed as new models are added and new data is collected. This ensures the leaderboard reflects the latest performance trends across the AI ecosystem.
The pool is structured to represent 22 specific demographic groups across three key axes in the US and UK. While focused on US/UK for the core study, the pool expands to include participants from Asia-Pacific, Middle East, North Africa, and China expat communities.
We designed a multi-faceted evaluation framework grounded in real-world use cases and comparative human judgment. Our methodology was built on four pillars: comparative assessment, multi-dimensional metrics, user-driven scenarios, and a human-first judgment process.
You can explore the full HUMAINE leaderboard data—including demographic and task-level analysis—on our dedicated app on Hugging Face. Datasets are available; our announcement blog can be found on the Prolific blog.
An AI evaluation leaderboard ranks artificial intelligence models based on specific benchmarks. The HUMAINE leaderboard is unique because it uses statistically rigorous, multi-dimensional human feedback to measure real-world performance—like reasoning, trust, and communication style—rather than just technical test scores.
Prolific brings deep expertise in human-centered research and access to a diverse, representative pool of verified participants. This ensures that evaluations are fair, reliable, and grounded in real user experience.
An AI leaderboard is a public ranking of AI models, typically large language models, ordered by performance on a defined set of tasks or evaluations. Most leaderboards aggregate automated benchmark scores (e.g. MMLU, GSM8K, HumanEval). Human-preference leaderboards like HUMAINE and Chatbot Arena instead rank models by side-by-side human judgments in real conversations.